

目錄
就在馬斯克發佈grok3,sam altman 還在猶豫要不要開源時,剛剛梁文鋒作為co-authors攜deepseek研究團隊丟出重磅研究論文成果,DeepSeek 發佈了最新的研究成果——原生稀疏注意力(Native Sparse Attention, NSA)! 這項技術有望大幅提升下一代大語言模型處理長文本的能力,同時還能兼顧效率,可謂是 LLM 領域又一里程碑式的進展!

簡單來説,論文的核心貢獻如下:
LLM 長文本能力再突破!DeepSeek 發佈原生稀疏注意力 NSA:硬件友好又高效,訓推一體化!
廢話不多説,我們一起來扒一扒這篇論文:
先了解一下論文的背景
近年來,我們見證了長文本建模在 AI 領域的重要性日益凸顯。無論是深度推理、代碼庫生成、還是多輪對話,都離不開模型對長序列信息的有效處理能力。像 OpenAI 的 o-series 模型、DeepSeek-R1、以及 Google Gemini 1.5 Pro 等,都展現了處理超長文本的強大潛力。
然而,傳統 Attention 機制的計算複雜度隨着序列長度的增加而呈平方級增長,這成為了制約 LLM 發展的關鍵瓶頸。計算成本高昂,延遲成為問題, 如何在保證模型性能的同時,提升長文本處理的效率,成為了亟待解決的難題
稀疏注意力應運而生,它被認為是提升效率,同時維持模型能力的有希望的方向。DeepSeek 的 NSA 技術正是在這個方向上邁出了重要一步!
DeepSeek NSA:原生稀疏注意力,訓推一體化,硬件友好
DeepSeek 提出的 NSA (Native Sparse Attention,原生稀疏注意力) 機制,巧妙地將算法創新與硬件優化相結合,旨在實現高效的長文本建模。
NSA 的核心亮點可以概括為以下兩點:
1.動態分層稀疏策略: NSA 採用了一種動態分層的稀疏策略,結合了粗粒度的 Token 壓縮 和 細粒度的 Token 選擇。這種策略既能保證模型對全局上下文的感知,又能兼顧局部信息的精確性
2.兩大關鍵創新:
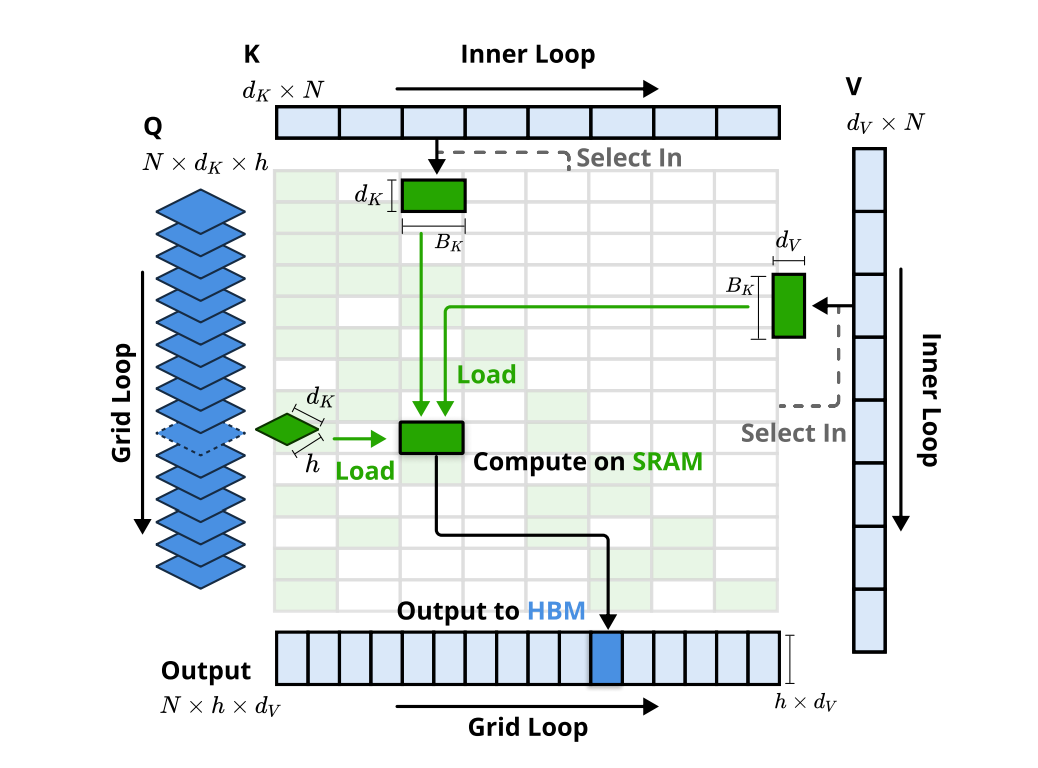
算術強度平衡的算法設計與硬件優化: NSA 通過精巧的算法設計,並針對現代硬件進行了實現優化,顯著提升了計算速度
端到端可訓練: NSA 支持端到端訓練,這意味着它不僅在推理階段高效,還能減少預訓練的計算量,同時不犧牲模型性能!
💪實驗效果驚豔:性能不降反升,速度大幅提升!
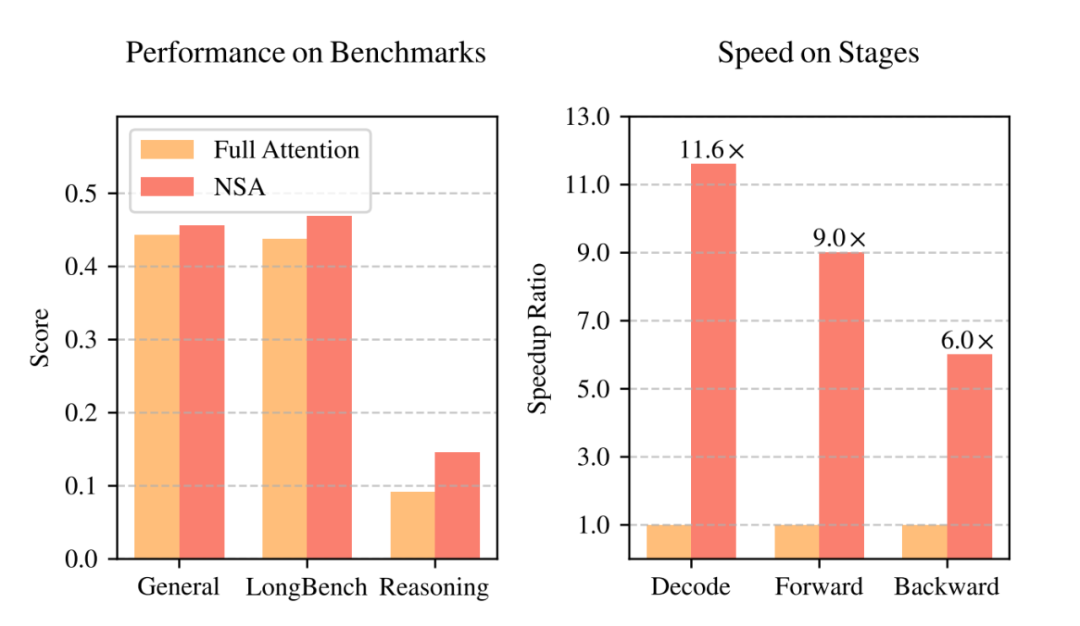
實驗結果令人振奮!如圖 1 所示,在通用基準測試、長文本任務和指令推理方面,使用 NSA 預訓練的模型性能不僅沒有下降,反而超越了 Full Attention 模型!
更重要的是,在處理 64k 長度的序列時,NSA 在解碼、前向傳播和反向傳播等各個階段都實現了顯著的速度提升,最高可達 11.6 倍! 這充分證明了 NSA 在模型生命週期各個階段的效率優勢
🤔 現有稀疏注意力方法的侷限性
論文也深入分析了現有稀疏注意力方法的侷限性,主要體現在兩個方面:
1.推理效率的“假象”: 很多方法雖然在理論上實現了稀疏計算,但在實際推理延遲方面提升有限。這主要是因為:
• 階段限制的稀疏性: 例如,有些方法只在自迴歸解碼時應用稀疏性,但在預填充階段仍然需要大量計算
• 與先進 Attention 架構的不兼容性: 一些稀疏注意力方法難以適配像 MQA 和 GQA 這樣的現代高效解碼架構,導致內存訪問瓶頸依然存在
2.可訓練稀疏性的“神話”: 許多方法主要關注推理階段的稀疏性,而忽略了訓練階段。這導致:
• 性能退化: 後驗應用稀疏性可能導致模型偏離預訓練的優化軌跡。
• 訓練效率需求: 長序列訓練對於提升模型能力至關重要,但現有方法在訓練效率方面存在不足。
• 不可訓練的組件: 一些方法引入了不可微的離散操作,阻礙了梯度傳播,限制了模型學習最佳稀疏模式的能力。
• 反向傳播效率低下: 一些理論上可訓練的方法,在實際訓練中效率低下,例如 Token 粒度的選擇策略可能導致非連續的內存訪問,影響硬件利用率。
🧩 NSA 的核心元件:分層稀疏,逐層最佳化
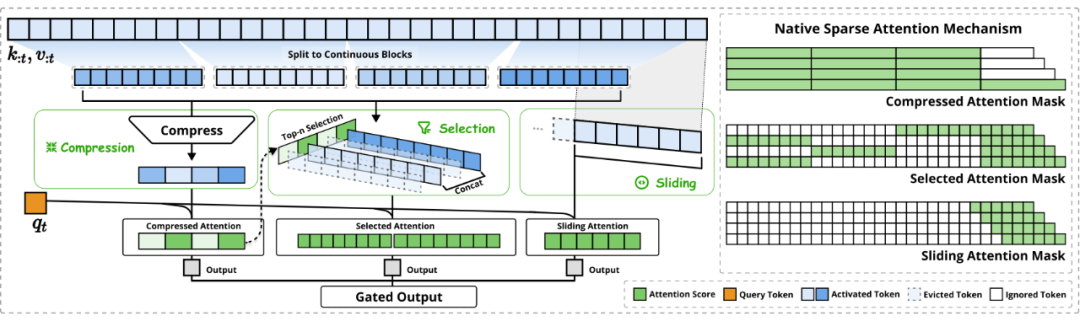
為了克服上述侷限性,NSA 架構採用了分層 Token 建模,並通過三個並行的注意力分支處理輸入序列:
1. 壓縮注意力 (Compressed Attention): 處理粗粒度的模式,通過壓縮 Token 塊來捕獲全局信息。
2. 選擇注意力 (Selected Attention): 處理重要的 Token 塊,選擇性地保留細粒度的信息。
3. 滑動窗口注意力 (Sliding Window Attention): 處理局部上下文信息。
這三個分支的輸出通過一個門控機制進行聚合。為了最大化效率,NSA 還專門設計了硬件優化的 Kernel
寫在最後:
DeepSeek 的 NSA 技術為長文本建模帶來了新的突破。它不僅在性能上超越了傳統的 Full Attention 模型,更在效率方面實現了顯著的提升,尤其是在長序列場景下。NSA 的 硬件友好設計 和 訓推一體化特性,使其在實際應用中更具優勢,有望加速下一代 LLM 在長文本處理領域的應用落地。
這項研究無疑為稀疏注意力領域帶來了新的思路和方向。未來,我們期待看到更多基於 NSA 技術的創新應用,共同推動 AI 技術的進步!
参考:
https://arxiv.org/pdf/2502.11089







{kind=link}