
目錄
OpenAI 剛剛發佈了一份研究報告,主題是關於人工智能在競技編程領域的進展。他們展示了自家的大模型是如何一步步從“編程小白”成長為可以和頂尖程序員 PK 的“高手”

競技編程,可能有些朋友不太熟悉,簡單來説就是比拼編程能力和算法技巧的比賽,像 ACM、ICPC、Codeforces 這些平台就聚集了很多編程高手報告裏提到,最初的模型表現平平,在編程方面顯得比較吃力。
但關鍵的轉折點是 大型推理模型 的出現,特別是結合了 強化學習 (Reinforcement Learning) 進行訓練之後,o1到o3模型變強的“心路歷程”,但是方法依然是個迷,問就是四個字:強化學習
故事的開端:強化學習賦能 “推理” 大腦
OpenAI 這次報告的核心,其實還是他們一直強調的 強化學習 (Reinforcement Learning, RL) 。報告一開始就明確指出,RL 是提升大型語言模型 (LLMs) 在複雜編程和推理任務上性能的 關鍵驅動力
為了驗證 RL 的效果,OpenAI 首先推出了 通用推理模型 OpenAI o1。這個模型在訓練時,特別注重提升 鏈式思考 (chain-of-thought reasoning) 能力。簡單來説,就是讓 AI 學會像人類一樣,一步一步地分析問題、拆解難題,最終找到解決方案
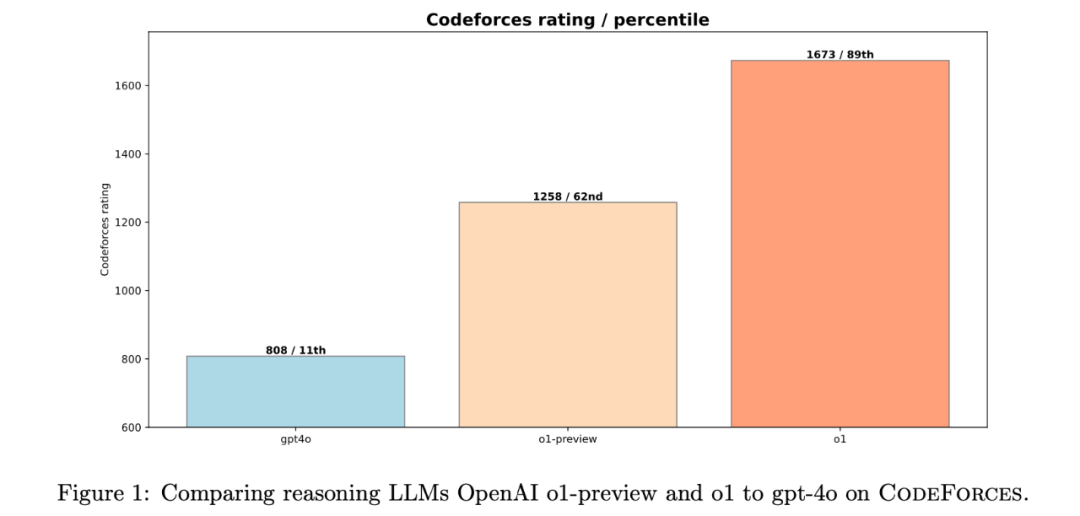
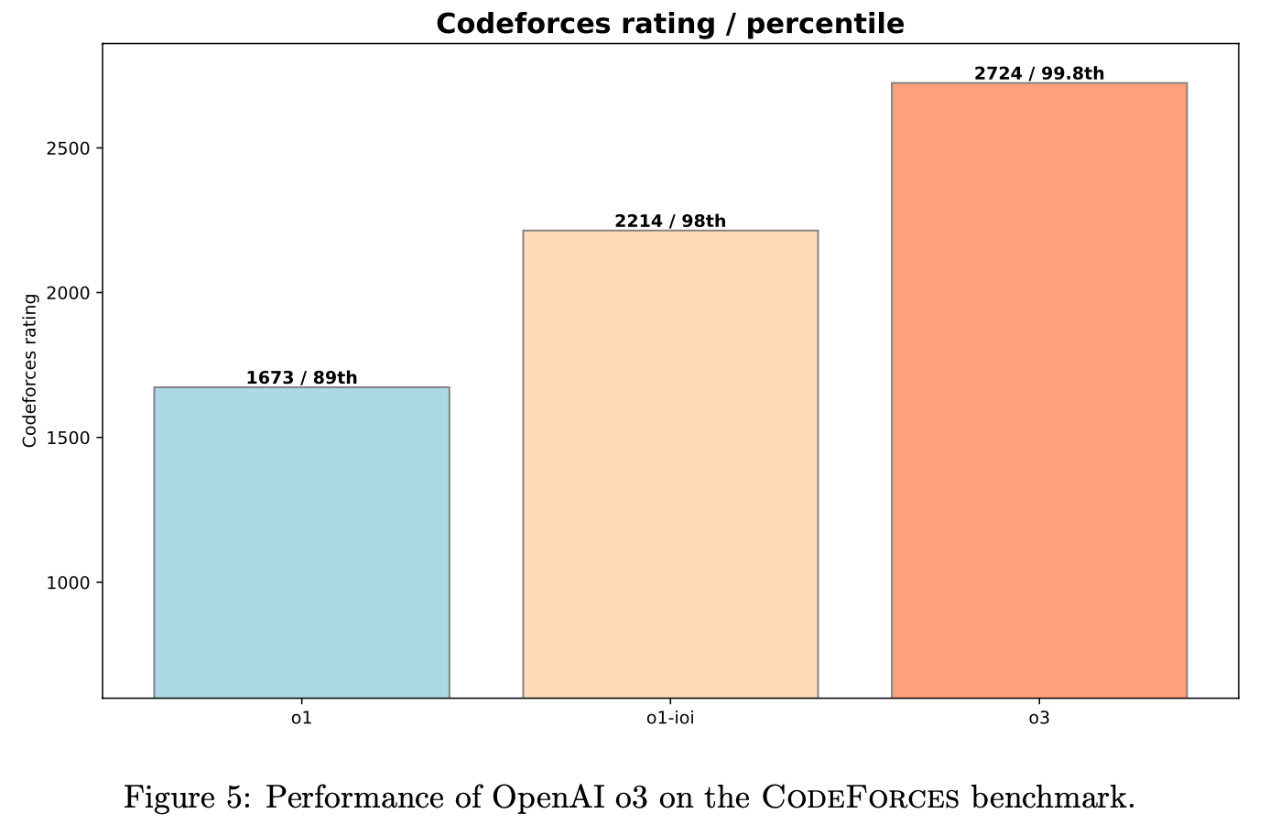
數據説話,效果驚人! 在模擬的 Codeforces 競賽環境中,o1 模型的表現相比之前的模型 大幅提升。 它的 Elo 評分從 1258 分 (62nd percentile) 直接躍升到 1673 分 (89th percentile)!
挑戰 IOI:特訓模型 + 人工策略 “雙劍合璧”
OpenAI 的目標遠不止於此。為了挑戰更具含金量的 國際信息學奧林匹克競賽 (IOI),他們對 o1 模型進行了 專項強化訓練,並打造了 o1-ioi 模型。同時,為了確保在 IOI 這種高強度競賽中取得好成績,研究團隊還 “祭出” 了 手工打造的測試時策略 (hand-crafted test-time strategies)
這些策略,可以理解為人類專家為 AI 模型 “量身定製” 的一套競賽技巧 “組合拳”,包括:
• 子任務分解 (Subtask Decomposition): 將 IOI 複雜問題拆解成更小的、更易於解決的子任務。IOI 競賽評分也是基於子任務的,這個策略非常契合競賽特點
• 大規模採樣 (Large-Scale Sampling): 針對每個子任務,模型生成 10,000 個候選解決方案,通過 “廣撒網” 的方式,提高找到正確答案的概率
• 聚類與重排序 (Clustering and Reranking): 對生成的候選方案進行聚類,然後根據預設的評分標準進行重排序,選出最優的方案進行提交
• 模型生成測試用例與驗證 (Model-Generated Test Inputs & Validators): 利用模型自身生成測試用例和驗證器,用於評估和篩選候選方案的正確性。
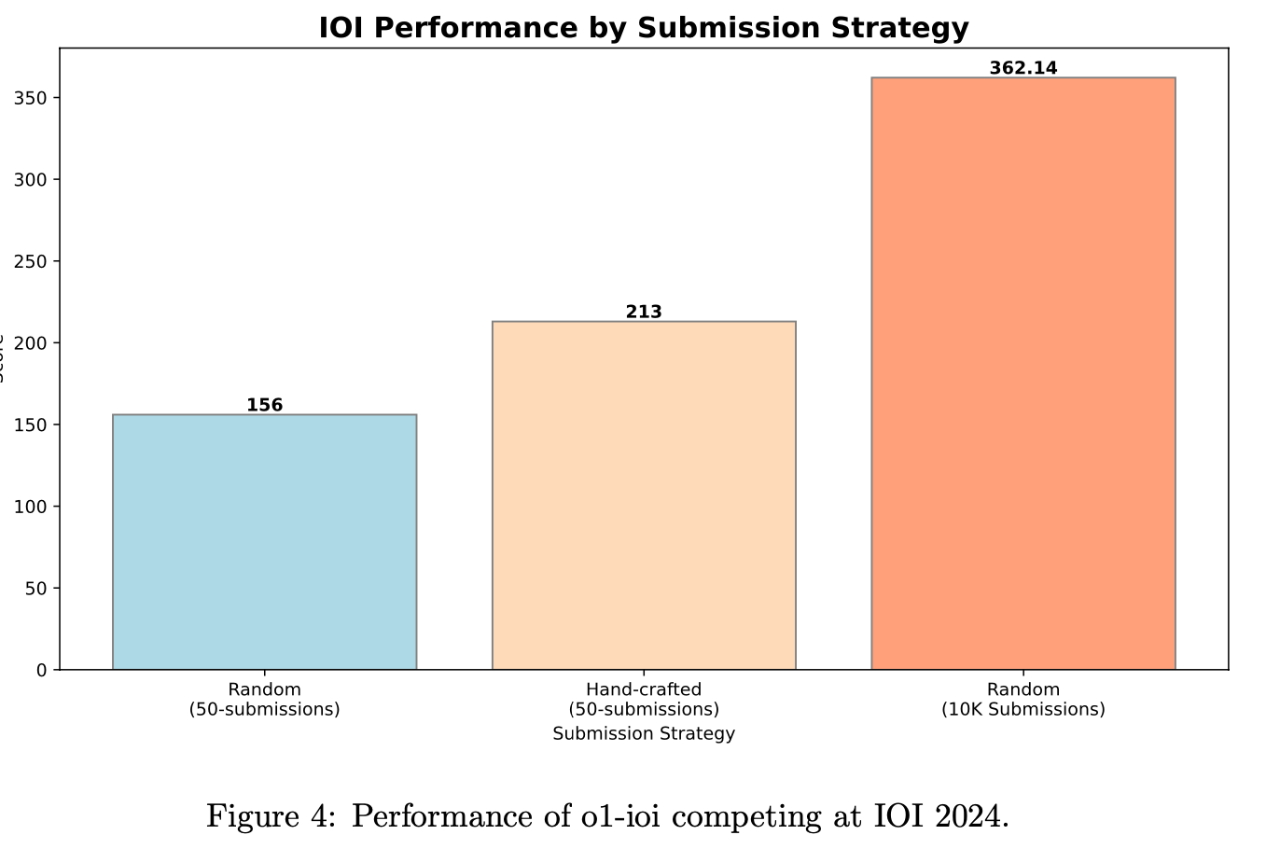
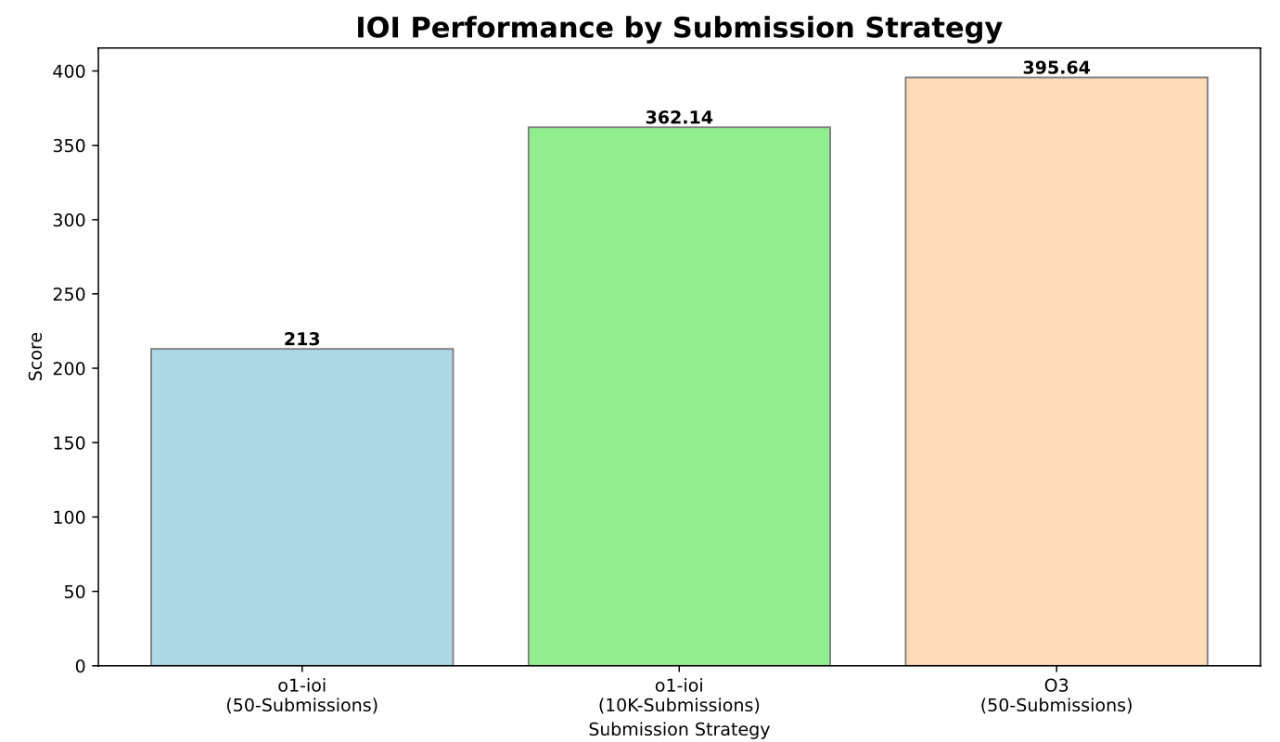
“人機協作” 威力顯現! 在 手工策略 的加持下,o1-ioi 模型在 IOI 競賽中獲得了 49% 的排名,得分 213 分。更令人振奮的是,當 OpenAI 放寬提交次數限制 (從官方的每題 50 次放寬到 10,000 次) 後,o1-ioi 模型竟然 一舉奪得金牌!得分高達 362.14 分
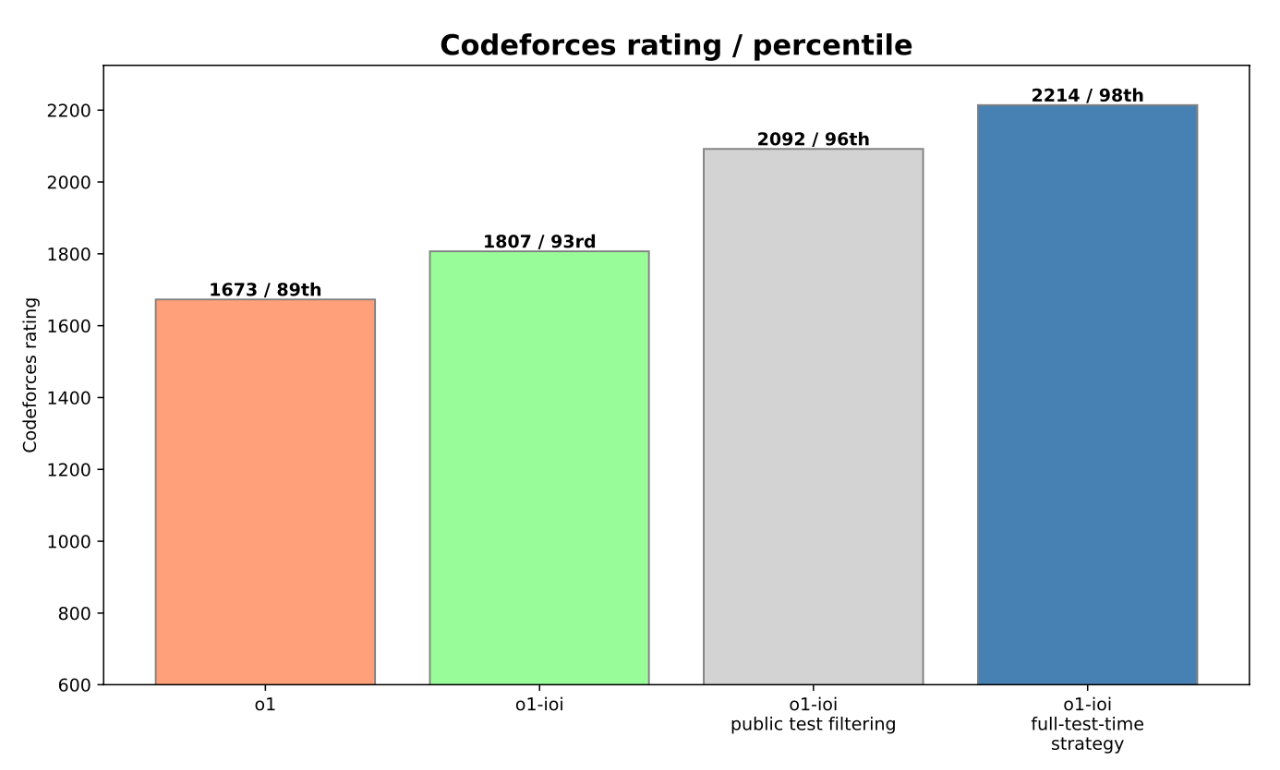
報告中還提到,這些 手工策略 非常有效,為 o1-ioi 的 IOI 成績 提升了約 60 分,在 Codeforces 上的 percentile 排名也 提升了 5% (從 93% 提升到 98%, Elo 評分達到 2214 分)。
純粹 RL 的力量:o3 模型 “無招勝有招” 的自主進化
雖然 o1-ioi 模型取得了亮眼的成績,但 OpenAI 並沒有滿足於 “人機結合” 的模式。他們更進一步,推出了 新一代模型 o3。這次,他們想要探索 純粹強化學習 的極限—— 完全不依賴任何人工策略,只通過 RL 訓練,AI 能否在競技編程領域達到頂峯?
o3 模型在 Codeforces 上的 Elo 評分更是達到了 2724 分 (99.8th percentile), 全球排名 Top 0.2%, 接近 全球 Top 175 名 的水平!
o3 模型在沒有任何人工策略輔助的情況下,竟然在官方 IOI 競賽的嚴格約束下,也成功斬獲金牌! 🏆 得分高達 395.64 分,進一步超越金牌線
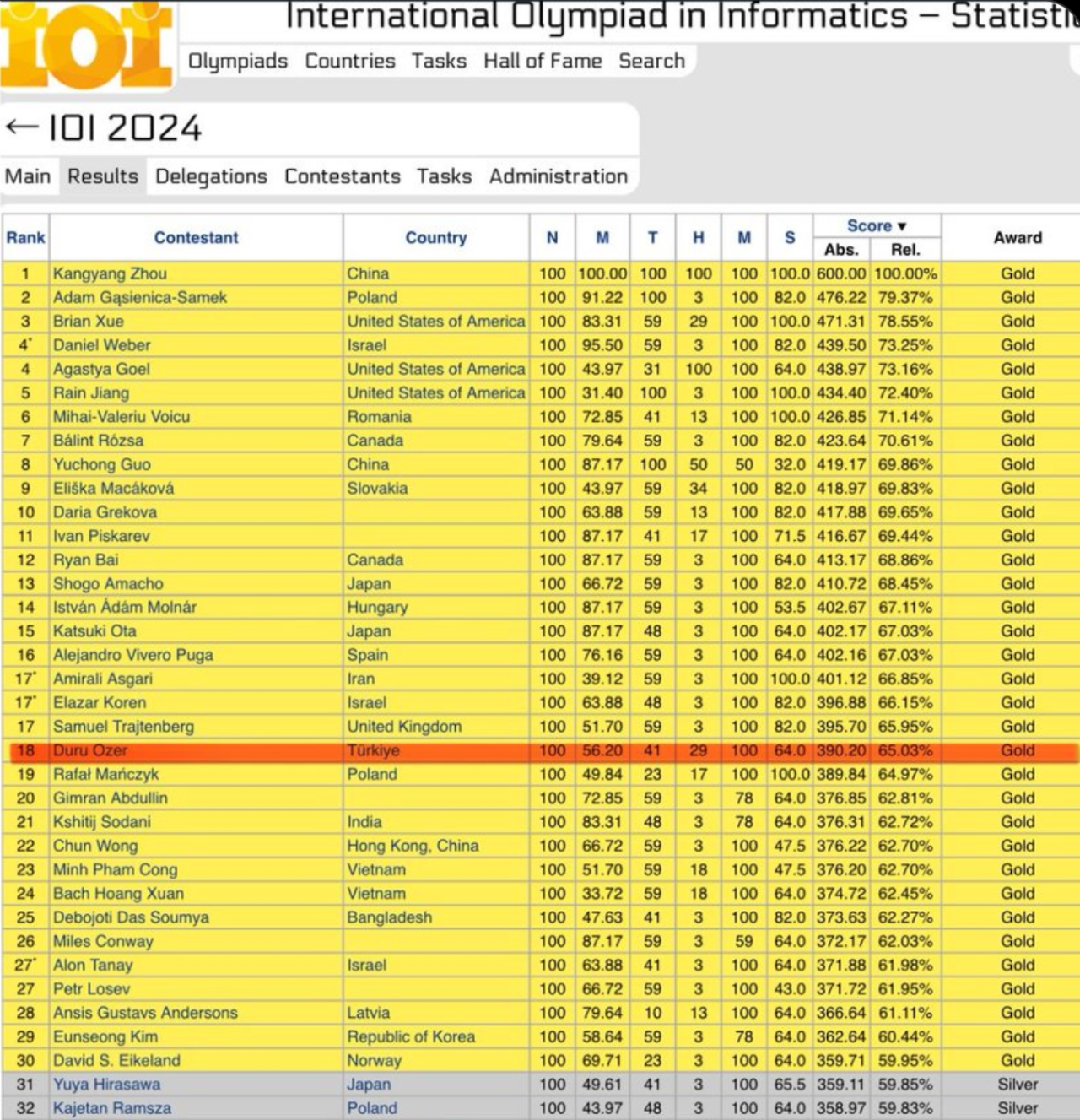
OpenAI o3 在 2024 年國際信息學奧林匹克競賽(IOI)中獲得 395.64分(滿分 600 分),獲得金牌,世界排名第 18 位。該模型沒有受到這些數據的污染,並且使用了 50 次提交限制。這也印證了奧特曼的説法今年我們很可能會看到超人的編碼模型
“自主進化” 的解題策略:暴力驗證,殊途同歸
更深入地分析 o3 模型的 解題過程 (chain of thought),研究人員發現,o3 模型竟然 自主領悟 並發展出了一套 測試時策略!其中一個策略,與人類程序員的常用技巧 不謀而合:
1. 先編寫一個簡單粗暴的 “暴力解法” (brute-force solution),確保程序的基本功能正確2. 再利用這個 “暴力解法”,去驗證更復雜、更優化的算法,確保優化後的算法在邏輯上也是正確的
這種先 “保底” 再 “優化” 的思路,是不是和我們人類程序員在競賽中常用的策略 如出一轍?AI 不僅學會了編程,還學會了 人類的思考方式, 這才是 o3 模型最令人震撼的地方!
不止於競賽:RL 提升 AI 的 “通用” 編程能力
競技編程的成功,只是 OpenAI 這次研究的一個側面。他們還評估了這些模型在 軟件工程 (Software Engineering, SWE) 任務中的表現,使用了 HackerRank Astra 和 SWE-bench Verified 兩個行業benchmark 數據集
競技編程的成功,只是 OpenAI 這次研究的一個側面。他們還評估了這些模型在 軟件工程 (Software Engineering, SWE) 任務中的表現,使用了 HackerRank Astra 和 SWE-bench Verified 兩個行業benchmark 數據集
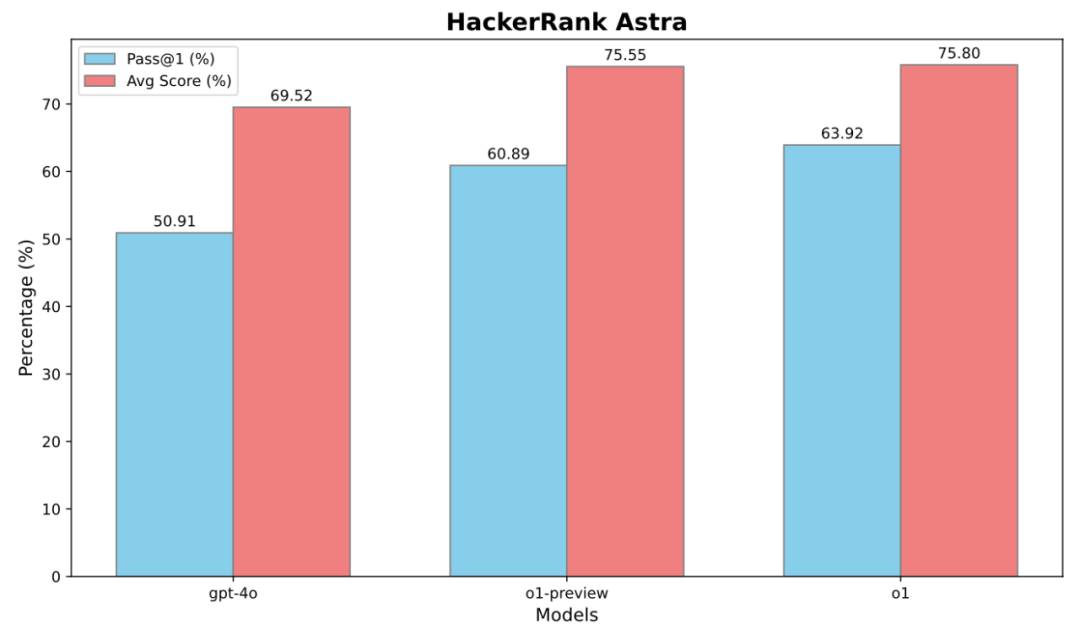
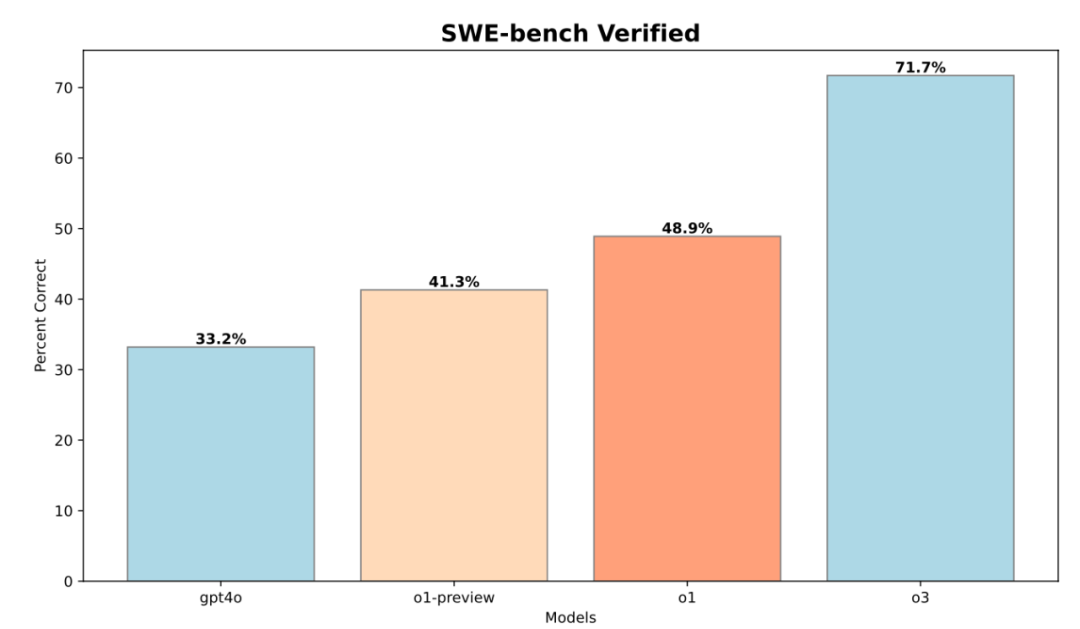
o3 模型在 SWE-bench Verified 數據集上,相比 o1 模型,Pass@1 提升了 22.8%! 這表明,強化學習不僅能提升 AI 的競賽編程能力,也能有效提升其在更廣泛的軟件開發領域的應用能力
報告中關鍵數據回顧:
Codeforces Elo 評分: o1-preview: 1258 (62nd percentile), o1: 1673 (89th percentile), o1-ioi: 2214 (98th percentile), o3: 2724 (99.8th percentile, Top 0.2%, 全球 Top 175 左右)
IOI 競賽得分: o1-ioi (官方約束): 213 分 (49th percentile), o1-ioi (放寬約束): 362.14 分 (金牌), o3 (官方約束): 395.64 分 (金牌). 手工策略為 o1-ioi IOI 提升 60 分, Codeforces percentile 提升 5%
• SWE-bench 性能提升: o3 相比 o1, Pass@1 提升 22.8%. HackerRank Astra 數據也顯示類似提升
Codeforces 模擬競賽評估方法 (Appendix B):
• 使用 Division 1 級別 競賽題目 (2023 年底至 2024 年後)。
• 採用 完整測試集 (full test suite), 模擬官方 Codeforces 評分環境。
• 嚴格遵守 時間/內存限制
• 進行 污染檢查 (contamination check),確保測試題目未在模型訓練數據中出現
• 使用 Elo 評分系統 評估模型在 Codeforces 上的等級和 percentile 排名。
IOI 代碼示例 (Appendix C):
報告中附錄 C 提供了 o1-ioi 模型在 IOI 競賽中生成的 C++ 代碼示例, 包括 Nile 和 Message 兩道題目的部分代碼。例如,Nile 題目的代碼中使用了 Union-Find 數據結構 來解決連通性問題。(感興趣的朋友可以去原文附錄 C 查看代碼細節)
寫在最後:
這份報告就是在講強化學習的威力,只不過OpenAI只告訴了結果,現在大家都知道了,因為DeepSeek R1已經證明了同樣的事情,但是DeepSeek附送了詳細的技術報告,告訴了強化學習實施的方法和過程
參考:







{kind=link}