
目錄
DeepSeek放大招!DeepSeek-R1-Lite-Preview 震撼登場!推理能力超強,沒有黑盒,實時展示推理思考過程,直接叫板OpenAI的o1-preview!
直接看性能
DeepSeek-R1-Lite 預覽版模型在美國數學競賽(AMC)中難度等級最高的 AIME 以及全球頂級編程競賽(codeforces)等權威評測中,大幅超越了 GPT4o,甚至o1-preview 等知名模型
在六個不同基準測試(AIME 2024、MATH、GPQA Diamond、Codeforces、LiveCodeBench、ZebraLogic)中的表現
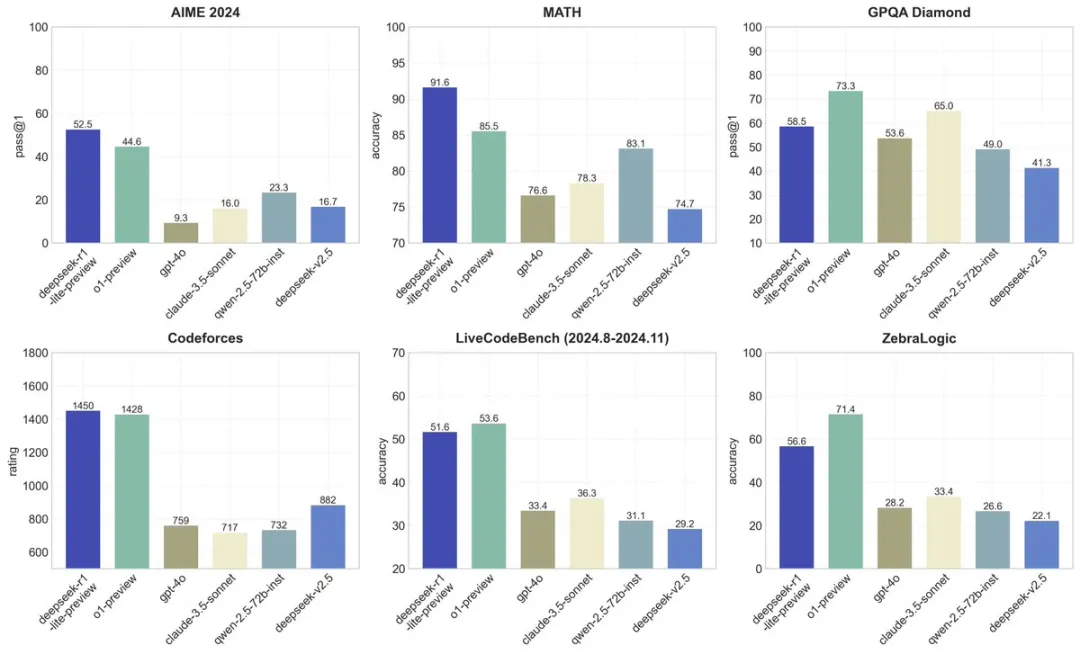
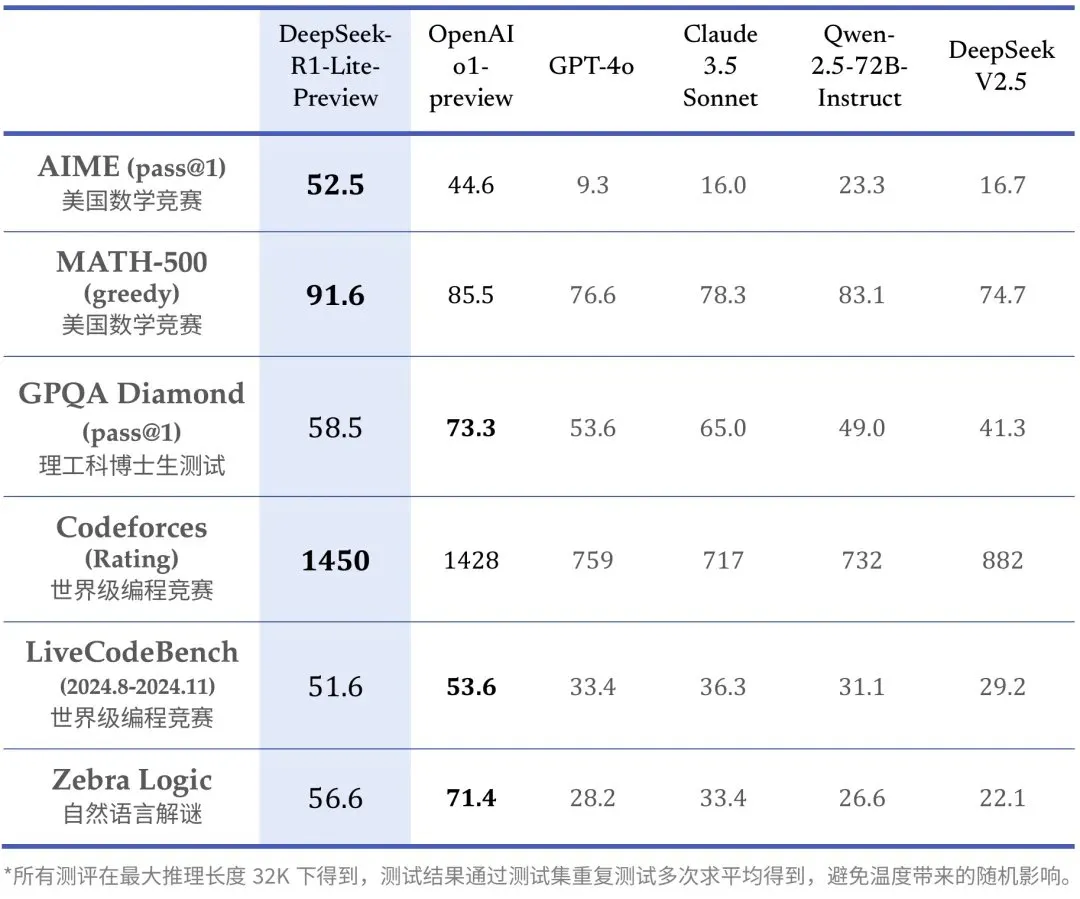
AIME 2024 :pass@1,模型第一次嘗試就給出正確答案的百分比
deepseeker-r1-lite-preview 的表現最佳,達到 52.5%。o1-preview 緊隨其後,為 44.6%
MATH :accuracy,模型在數學推理題上的正確率
deepseeker-r1-lite-preview 依然領先,正確率為 91.6%。o1-preview 緊隨其後(85.5%),與其他模型拉開較大差距
GPQA Diamond:pass@1,模型在高難度問題上的首答正確率
o1-preview 領先,達到 73.3%,deepseeker-r1-lite-preview 緊隨其後,為 58.5%
Codeforces:rating,模型在編程挑戰賽中的分數
deepseeker-r1-lite-preview 領先,分數為1450 , o1得分1428
LiveCodeBench:accuracy,編程任務的正確率(2024年8月至11月)
o1-preview 小幅領先,正確率為 53.6%。deepseeker-r1-lite-preview 緊隨其後,為 51.6%
ZebraLogic :accuracy,評估邏輯推理任務的正確率
o1-preview 佔據第一,為 71.4%,deepseeker-r1-lite-preview 緊隨其後,為 56.6%
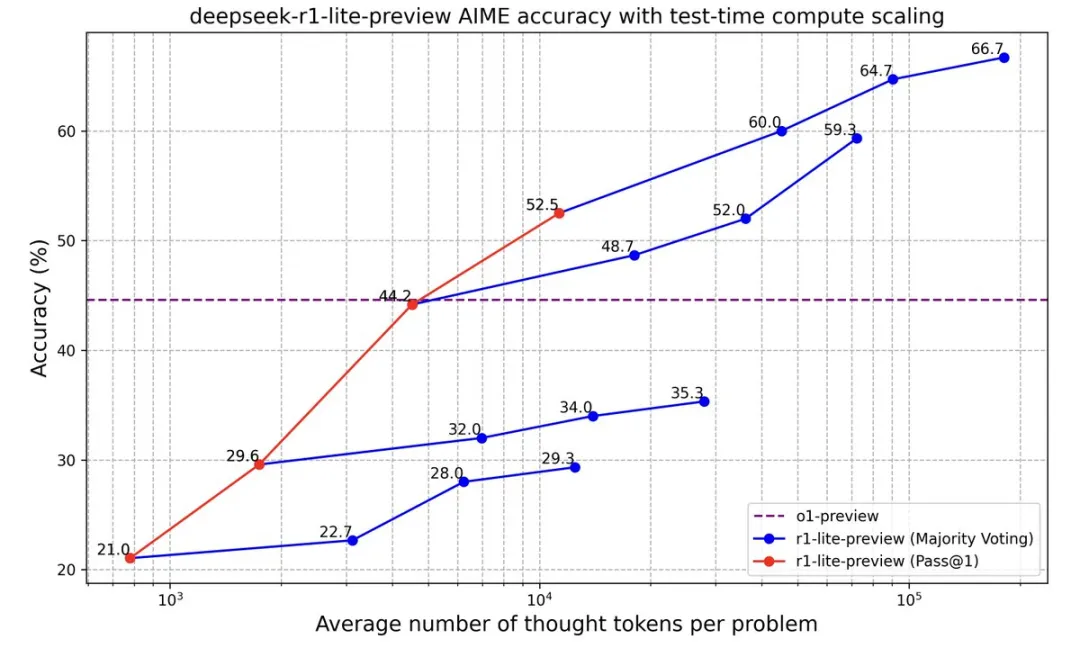
DeepSeek-R1-Lite-Preview推理縮放
更長的推理,更好的性能。隨着思維長度的增加,DeepSeek-R1-Lite-Preview 在 AIME 上的得分穩步提高,這與OpenAI o1 提出推理縮放規律是一致的,由此也可以説明推理縮放具有巨大的潛力
DeepSeek-R1-Lite-Preview實測:
實時透明的思維過程! 讓你清清楚楚地看到AI的思考過程,不再是黑盒!
我測試了幾個經典問題:
9.11和9.8哪個大?
9.12和9.9哪个大?
單詞 “strawberry”(草莓)有幾個r?
單詞'blueberrycherryberrycarbonpherry'?有幾個r?
回答全都是一次性正確,並且實時的展示出了思考的過程
令我印象非常深刻,如果我沒記錯,這是我第一次在大模型上測試這些經典問題全部一次性答對,大家可以自己去試試










開源模型和API即將推出!
DeepSeek-R1-Lite 目前仍處於迭代開發階段,僅支持網頁使用,暫不支持 API 調用。DeepSeek-R1-Lite 所使用的也是一個較小的基座模型,無法完全釋放長思維鏈的潛力。正式版 DeepSeek-R1 模型將完全開源,公開技術報告,部署API
各路網友都在向OpenAI喊話,趕緊放出o1完整版,deepseek太強了,超出了想象







{kind=link}