
目錄
OpenAI的Sora驚豔亮相,以及現在眾多視頻生成模型其強大的視頻生成能力引發了熱議,甚至有人認為它已經初步具備了世界模型的雛形,能夠理解並運用物理規律。但事實果真如此嗎?字節跳動AI實驗室的研究人員對此提出了質疑,並開展了一項系統性的研究,旨在探究視頻生成模型是否真的能夠從視頻數據中學習物理規律

真相只有一個:即使加大數據和模型規模,視頻生成模型也學不會物理規律!
研究方法及實驗過程:
為了深入研究這個問題,字節跳動的研究人員設計了一系列嚴謹的實驗,涵蓋以下幾個方面:
泛化場景: 為了全面評估模型的泛化能力,研究人員設置了三種泛化場景:
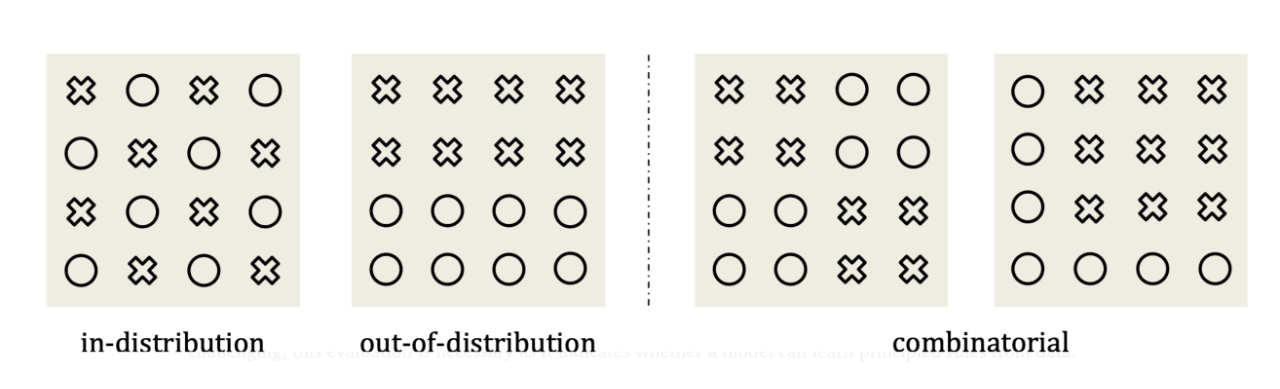
1.樣本內泛化(In-Distribution,ID):訓練數據和測試數據來自相同的分佈,遵循相同的物理規律,並且處於相同的領域
2.樣本外泛化(Out-of-Distribution,OOD):測試數據包含訓練數據中未曾出現過的場景,例如不同的初始條件、物體屬性或環境設置。這更能體現模型對物理規律的理解程度,因為真正的物理規律應該能夠泛化到新的場景
3.組合泛化(Combinatorial Generalization):介於ID和OOD之間的一種場景,訓練數據中包含各種“概念”或物體,但並非所有可能的組合都出現過。模型需要學習如何將已有的知識組合起來,應用到新的組合場景中
物理任務: 實驗選擇了幾個由經典力學規律主導的物理事件,例如:
1.勻速直線運動:驗證模型是否理解慣性定律
2.完全彈性碰撞:驗證模型是否理解能量守恆和動量守恆定律
3.拋物運動:驗證模型是否理解牛頓第二運動定律
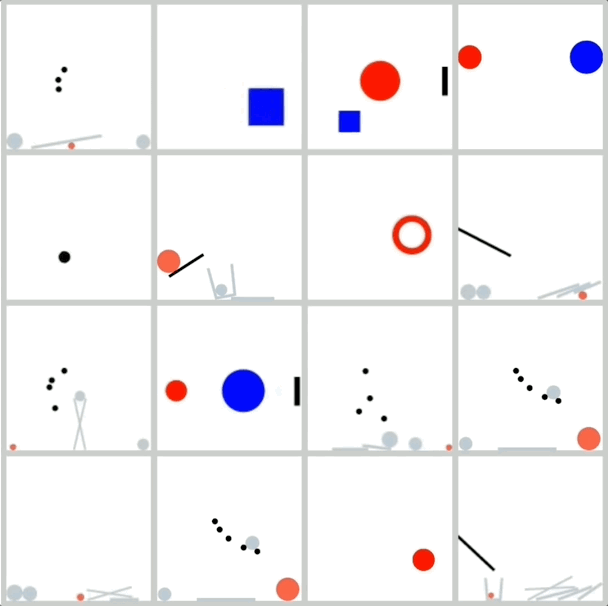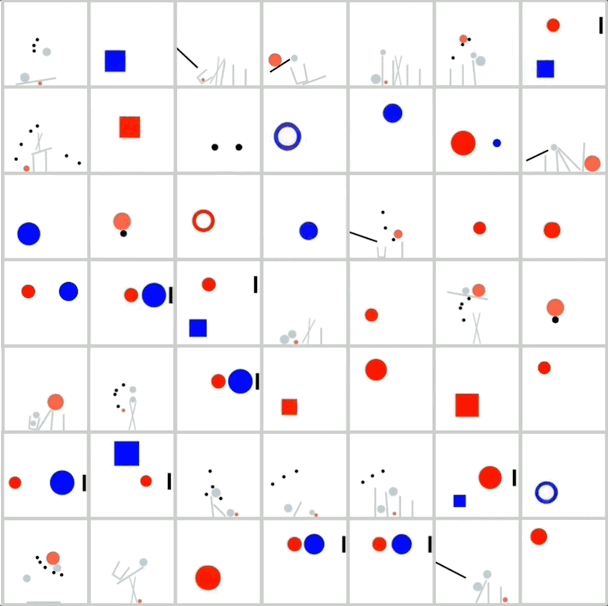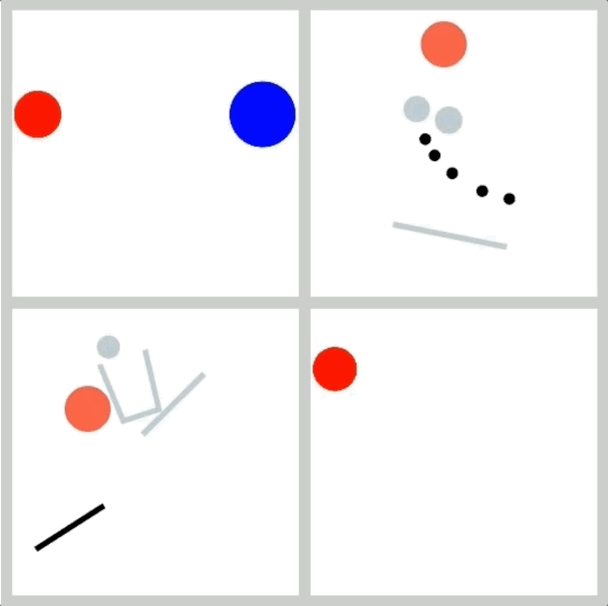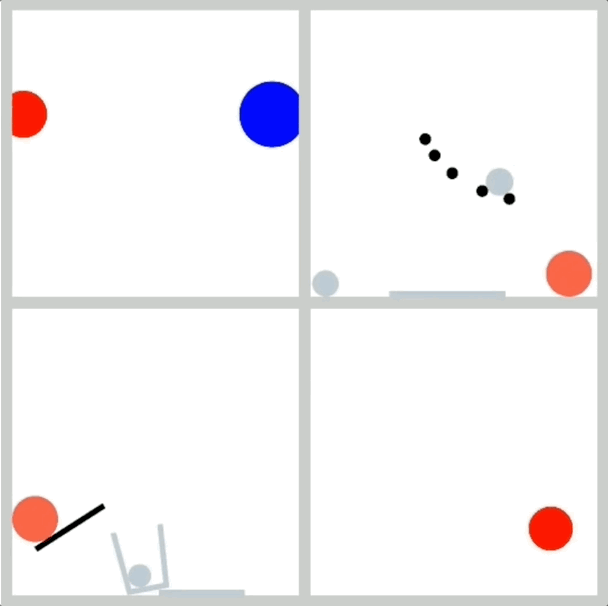
數據集: 為了避免紋理等複雜因素的干擾,研究人員專門開發了一個2D模擬器,使用簡單的幾何形狀生成數據,並確保數據量充足,以便進行規模擴展實驗
模型: 實驗使用了標準的視頻生成模型(Diffusion Model),並重點研究了模型規模擴展的影響
實驗結果及分析:
樣本內泛化: 在ID泛化場景下,模型表現出色,隨着模型規模和數據量的增加,預測誤差逐漸減小
樣本外泛化: 然而,在OOD泛化場景下,模型的性能急劇下降,預測誤差遠高於ID泛化場景。即使增加數據量和模型規模,也無法顯著降低OOD誤差。這表明模型並沒有真正理解物理規律,而是記憶了訓練數據中的模式
組合泛化: 在組合泛化場景中,模型的性能介於ID和OOD之間。實驗結果表明,模型的組合泛化能力與模型容量和組合空間的覆蓋範圍密切相關。增加訓練模板的數量可以提高模型的組合泛化能力,而僅僅增加數據量則效果有限
進一步的分析:
研究人員還進行了一些額外的實驗,以深入理解模型的泛化行為和侷限性:
插值與外推: 模型展現出強大的插值能力,但在外推方面表現較差
記憶與泛化: 實驗表明,模型更傾向於記憶訓練數據,而不是學習通用的物理規律
數據檢索: 模型在檢索訓練數據時,會優先考慮顏色、大小,然後是速度和形狀
視覺信息的侷限性: 研究發現,僅依靠視覺信息可能不足以進行準確的物理建模
語言和數值信息的補充: 添加語言或數值信息對ID泛化有一定幫助,但對OOD泛化的提升有限
結語
這項研究表明,目前的視頻生成模型雖然能夠生成逼真的視頻,但距離真正理解物理規律還有很長的路要走。未來的研究需要探索更有效的學習方法,例如引入物理先驗知識、改進模型的推理能力等,才能使視頻生成模型更接近真正的世界模型
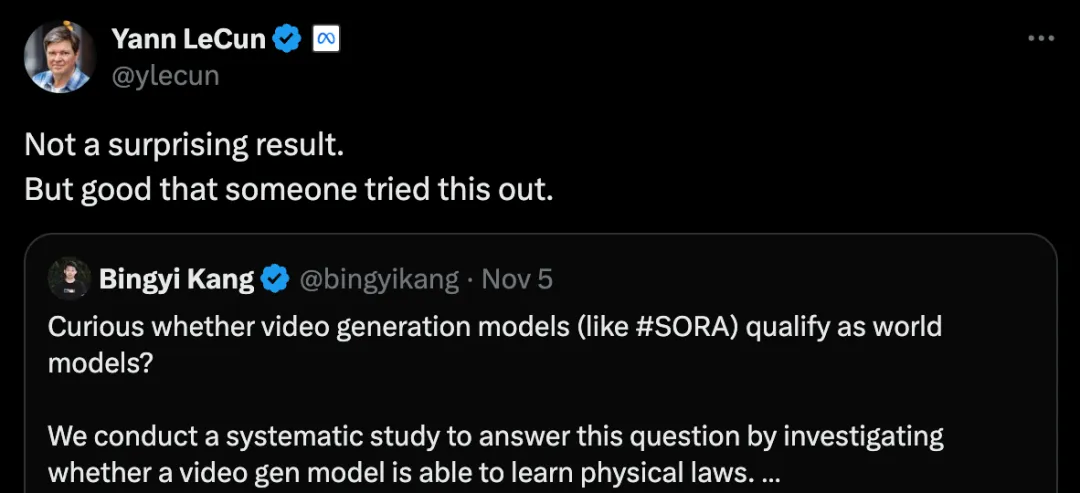
Yann LeCun評價:結果不出意外,但有人試過就好
作者信息:

Bingyi Kang
是 TikTok 的研究科學家。主要研究興趣是計算機視覺、多模態模型和決策制定。目標是開發能從各種觀察中獲取知識並與物理世界互動的代理。從以下幾個方面着手實現這一目標:1.處理現實生活中的任意數據(如長尾數據、無標記數據、合成數據等)
2.從觀測中恢復有關世界的(物理和語義)知識
3.有效和高效地利用這些知識進行交互此前是Sea AI lab的研究科學家。在新加坡國立大學獲得博士學位,導師是Jiashi Feng教授。在加州大學伯克利分校擔任客座研究員,師從 Trevor Darrell 教授。在攻讀博士學位期間,曾在 Facebook 人工智能研究院實習,與謝賽寧、Yannis Kalantidis 和 Marcus Rohrbach 共事。正在領導開發Depth Anything都可以系列
paper:
https://arxiv.org/pdf/2411.02385
code:
https://github.com/phyworld/phyworld
參考:
https://phyworld.github.io/#law_discovery







{kind=link}