

目錄
抄抄抄!Meta也抄起來了:開源版播客模型NotebookLlama來了
前段時間谷歌推出了播客模型NotebookLM,AI大神Andrej Karpathy連連點贊
剛剛Meta推出了對標谷歌NotebookLM開源版本NotebookLlama,它讓你用LLaMa模型把PDF直接變成播客!
體驗地址:
https://huggingface.co/spaces/gabrielchua/open-notebooklm
NotebookLlama核心流程是這樣的:
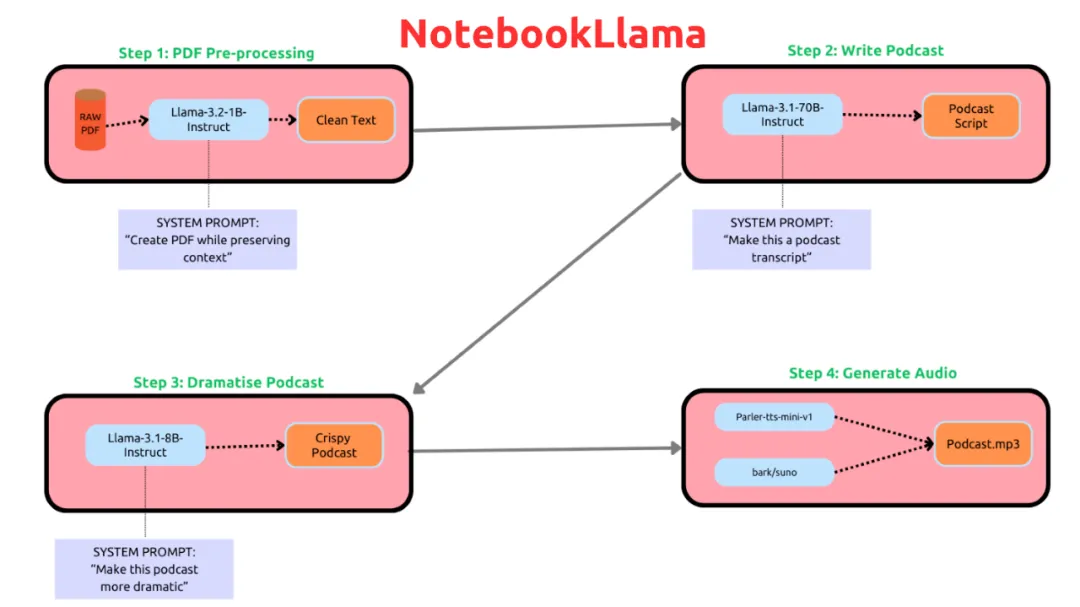
1B輕量級選手——預處理PDF: 就像一個勤勞的清潔工,把PDF裏的亂七八糟字符、編碼錯誤什麼的都清理乾淨,省得後面出幺蛾子。這步用了Llama-3.2-1B-Instruct模型,重點是隻清理垃圾,不改內容,不總結概括
70B重量級選手——寫播客稿: 這才是真正的主力輸出!用Llama-3.1-70B-Instruct模型,直接把文本變成播客稿,創意直接拉滿!當然,如果你覺得70B太壕,太吃顯存,也可以用Llama-3.1-8B-Instruct模型,作者也推薦大家多試試,看看哪個效果更好。據説70B模型寫出來的播客稿更具創意
8B調味大師——戲劇衝突MAX: 播客稿寫好了,還得加點兒戲劇衝突才夠味兒!Llama-3.1-8B-Instruct模型負責把稿子變得更刺激,更引人入勝!更重要的是,它返回的是對話元組,方便後續的TTS處理,數據結構101終於派上用場了!為了適配不同的TTS模型,還需要在prompt裏針對每個speaker做一些特定的設定
語音合成終極大殺器: 最後,用parler-tts/parler-tts-mini-v1和bark/suno模型把文字變成聲音,完美!這裏用到了兩個不同的TTS模型,speaker和prompt都是經過反覆實驗和模型作者建議才確定的。作者也鼓勵大家多多嘗試,説不定能找到更好的組合!需要注意的是,Parler需要transformers 4.43.3或更早版本,而前面的步驟需要最新版本,所以在最後一個notebook裏需要切換版本
敲黑板!重點來了!
你需要一個GPU服務器或者API provider來跑70B、8B和1B的LLaMa模型。70B模型需要大約140GB的顯存 (bfloat-16精度)
運行之前,先用huggingface-cli登錄,然後啓動jupyter notebook server,確保能下載LLaMa模型。需要Hugging Face的access token
先clone倉庫,安裝依賴:
git clone https://github.com/meta-llama/llama-recipes && cd llama-recipes/recipes/quickstart/NotebookLlama/ && pip install -r requirements.txt
每個notebook都有詳細的説明和建議,鼓勵大家修改prompt,嘗試不同的模型,看看哪個效果最好!
未來展望:
• TTS模型的自然度還有提升空間
• 可以用兩個agent辯論的方式來寫播客大綱
• 可以用405B模型寫稿
• 優化prompt
• 支持更多輸入格式,比如網站、音頻文件、油管鏈接等
學習資源:
https://betterprogramming.pub/text-to-audio-generation-with-bark-clearly-explained-4ee300a3713a
https://colab.research.google.com/drive/1dWWkZzvu7L9Bunq9zvD-W02RFUXoW-Pd?usp=sharing
https://colab.research.google.com/drive/1eJfA2XUa-mXwdMy7DoYKVYHI1iTd9Vkt?usp=sharing#scrollTo=NyYQ--3YksJY
https://replicate.com/suno-ai/bark?prediction=zh8j6yddxxrge0cjp9asgzd534
https://suno-ai.notion.site/8b8e8749ed514b0cbf3f699013548683?v=bc67cff786b04b50b3ceb756fd05f68c







{kind=link}