

目錄
OpenAI剛剛宣佈了一項重大技術突破,推出了名為sCM的新型連續時間一致性模型。sCM將開啓視頻,圖像、三維模型、音頻等實時、高質量、跨領域的生成式人工智能新階段

Diffusion models雖然在生成式 AI 領域混得風生水起,但採樣速度慢一直是它的硬傷。要走幾十步甚至幾百步才能生成一張圖片,效率低到讓人抓狂!雖然也有一些蒸餾技術,例如直接蒸餾、對抗蒸餾、漸進式蒸餾和變分分數蒸餾(VSD),可以加速採樣,但它們都有各自的侷限性,例如計算成本高、訓練複雜、樣本質量下降等現在,OpenAI 推出了全新的 sCM 模型,只需兩步採樣,速度提升 50 倍,性能直逼甚至超越擴散模型
sCM作為其前期一致性模型研究的延續和改進,簡化了理論框架,實現了大規模數據集的穩定訓練,同時保持了與領先擴散模型Diffusion models 相當的樣本質量,但僅需兩步採樣即可完成生成過程,OpenAI同時發佈了相關研究論文(兩位華人作者全都畢業於清華)

sCM是什麼?
sCM 和 Diffusion Models 不是完全不同的兩種模型,sCM 實際上是基於擴散模型的一種改進模型
更準確地説,sCM 是一種一致性模型 (Consistency Model),它借鑑了擴散模型的原理,並對其進行了改進,使其能夠在更少的採樣步驟下生成高質量的樣本
sCM 的核心是學習一個函數 fθ(xt, t),它能夠將帶噪聲的圖像 xt 映射到其在 PF-ODE 軌跡上的下一個時間步的清晰版本。這個過程並不是一步到位地去除所有噪聲,而是根據 PF-ODE 的方向,將圖像向更清晰的方向移動一步。在兩步採樣的情況下,sCM 會進行兩次這樣的映射,最終得到一個相對清晰的圖像。
因此,sCM 和擴散模型的關係可以概括為以下幾點:
sCM 是基於擴散模型的改進: sCM 依賴於擴散模型的 PF-ODE 來定義訓練目標和採樣路徑,它並不是一個完全獨立的模型
sCM 關注單步去噪: sCM 的訓練目標是學習一個能夠在單個時間步內進行有效去噪的函數,而不是像擴散模型那樣進行多步迭代去噪
sCM 採樣速度更快: 由於 sCM 只需要進行少量採樣步驟(例如兩步),因此其採樣速度比擴散模型快得多
sCM 並非一步到位: sCM 的單步去噪並非一步到位地去除所有噪聲,而是沿着 PF-ODE 的軌跡向更清晰的方向移動一步,多次迭代操作最終達到去噪效果
sCM:兩步到位,速度起飛!
OpenAI 基於之前的 consistency models 研究,並吸取了 EDM 和流匹配模型的優點,提出了 TrigFlow,一個統一的框架。這個框架牛逼的地方在於,它簡化了理論公式,讓訓練過程更穩定,還把擴散過程、擴散模型參數化、PF-ODE、擴散訓練目標以及 CM 參數化都整合成更簡單的表達式了!這為後續的理論分析和改進奠定了堅實的基礎
基於 TrigFlow,OpenAI 開發出了 sCM 模型,甚至可以在 ImageNet 512x512 分辨率上訓練 15 億參數的模型,簡直是史無前例!這是目前最大的連續時間一致性模型!
sCM 最牛逼的地方在於,它只需兩步採樣,就能生成與擴散模型質量相當的圖像,速度提升 50 倍!例如,最大的 15 億參數模型,在單個 A100 GPU 上生成一張圖片只需 0.11 秒,而且還沒做任何優化!如果再進行系統優化,速度還能更快,簡直是打開了實時生成的大門!🚀

sCM 到底有多強?
OpenAI 用 FID (Fréchet Inception Distance 它是一種用於評估生成模型生成圖像質量的指標)分數(越低越好)和有效採樣計算量(生成每個樣本所需的總計算成本)來評估 sCM 的性能。結果顯示,sCM 兩步採樣的質量與之前最好的方法相當,但計算量卻不到 10%!
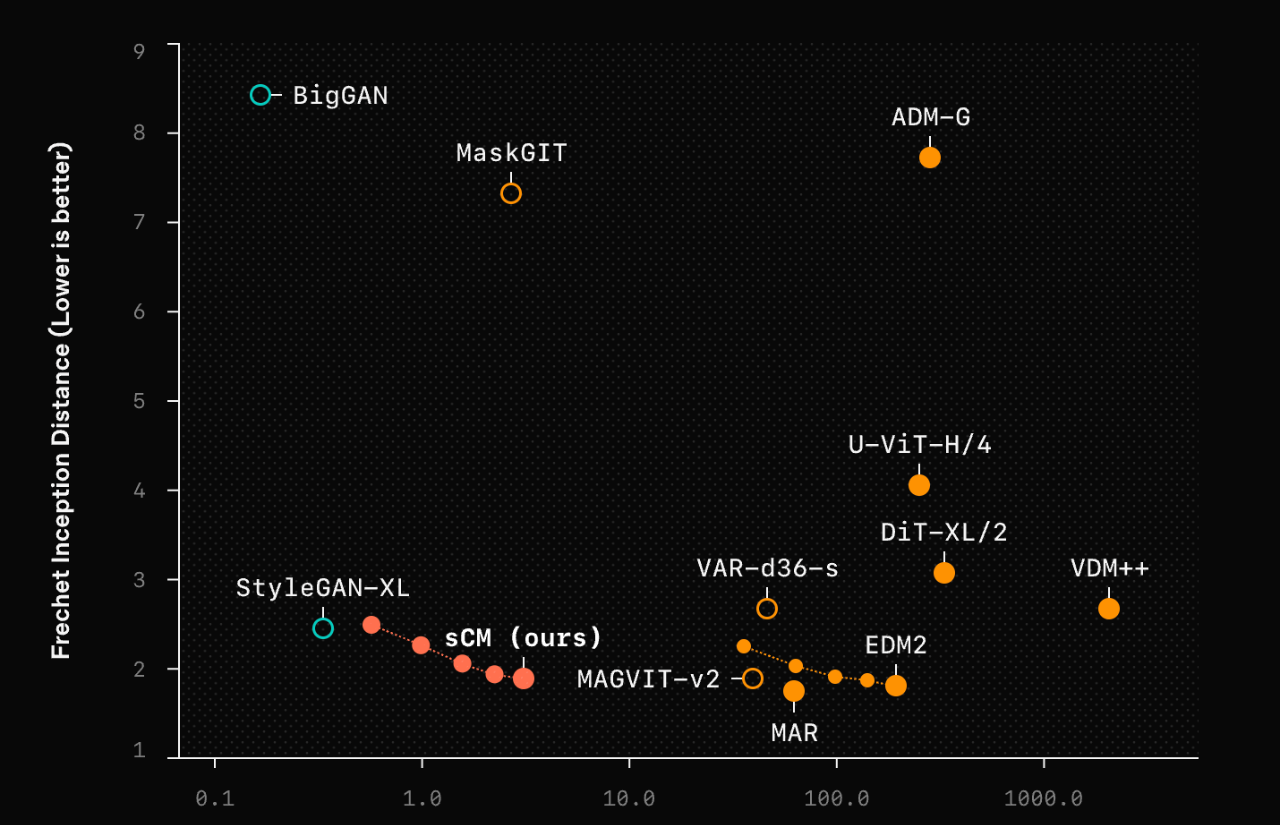
在 ImageNet 512x512 上,sCM 的 FID 分數甚至比一些需要 63 步的擴散模型還要好!在 CIFAR-10 上達到了 2.06 的 FID,ImageNet 64x64 上達到了 1.48,ImageNet 512x512 上達到了 1.88,與最好的擴散模型的 FID 分數差距在 10% 以內.
sCM 的核心改進:
除了 TrigFlow 框架,sCM 還引入了以下幾個關鍵改進,以解決連續時間一致性模型訓練不穩定的問題:
改進的時間條件策略(Identity Time Transformation): 使用 Cnoise(t) = t 而不是 Cnoise (t) = log(σα tan(t)),避免了當 t 趨近於 T 時出現的數值不穩定問題
位置時間嵌入 (Positional Time Embeddings): 使用位置嵌入代替傅里葉嵌入,避免了傅里葉嵌入帶來的不穩定性
自適應雙歸一化 (Adaptive Double Normalization): 解決了 AdaGN 層在 CM 訓練中帶來的不穩定性問題,同時保留了其表達能力
自適應權重 (Adaptive Weighting): 根據數據分佈和網絡結構自動調整訓練目標的權重,避免了手動調參的麻煩
切線歸一化/裁剪 (Tangent Normalization/Clipping): 控制梯度方差,進一步提高訓練穩定性
JVP 重新排列 (JVP Rearrangement) 和 Flash Attention 的 JVP 計算: 提升了大規模模型訓練的數值精度和效率
漸進式退火: 讓訓練過程更穩定,更容易擴展到大規模模型
擴散微調和切線預熱: 通過從預訓練的擴散模型進行微調和逐步預熱切線函數的第二項,進一步加速收斂並提高穩定性
sCM 的工作原理:
sCM 模型的核心思想是一致性,它試圖讓模型在相鄰時間步的輸出保持一致。通過學習 PF-ODE 的單步解,sCM 可以直接將噪聲轉換成清晰的圖像,一步到位!
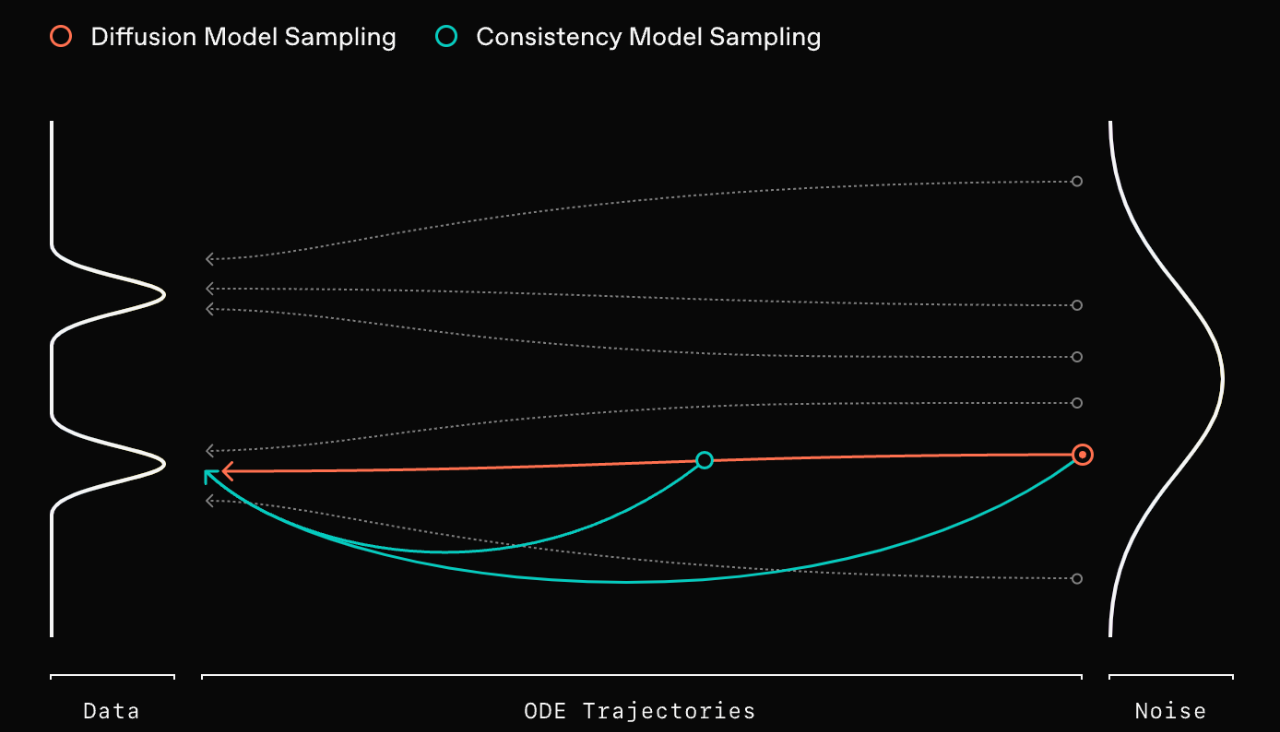
上圖中的路徑形象地説明了這一差異:藍線表示擴散模型的漸進採樣過程,而紅色曲線則表示一致性模型更直接、更快速的採樣過程。利用一致性訓練或一致性蒸餾等技術,可以訓練一致性模型,使其生成高質量樣本的步驟大大減少,這對需要快速生成樣本的實際應用非常有吸引力
sCM 模型通過從預訓練的擴散模型中蒸餾知識進行學習。一個關鍵的發現是:
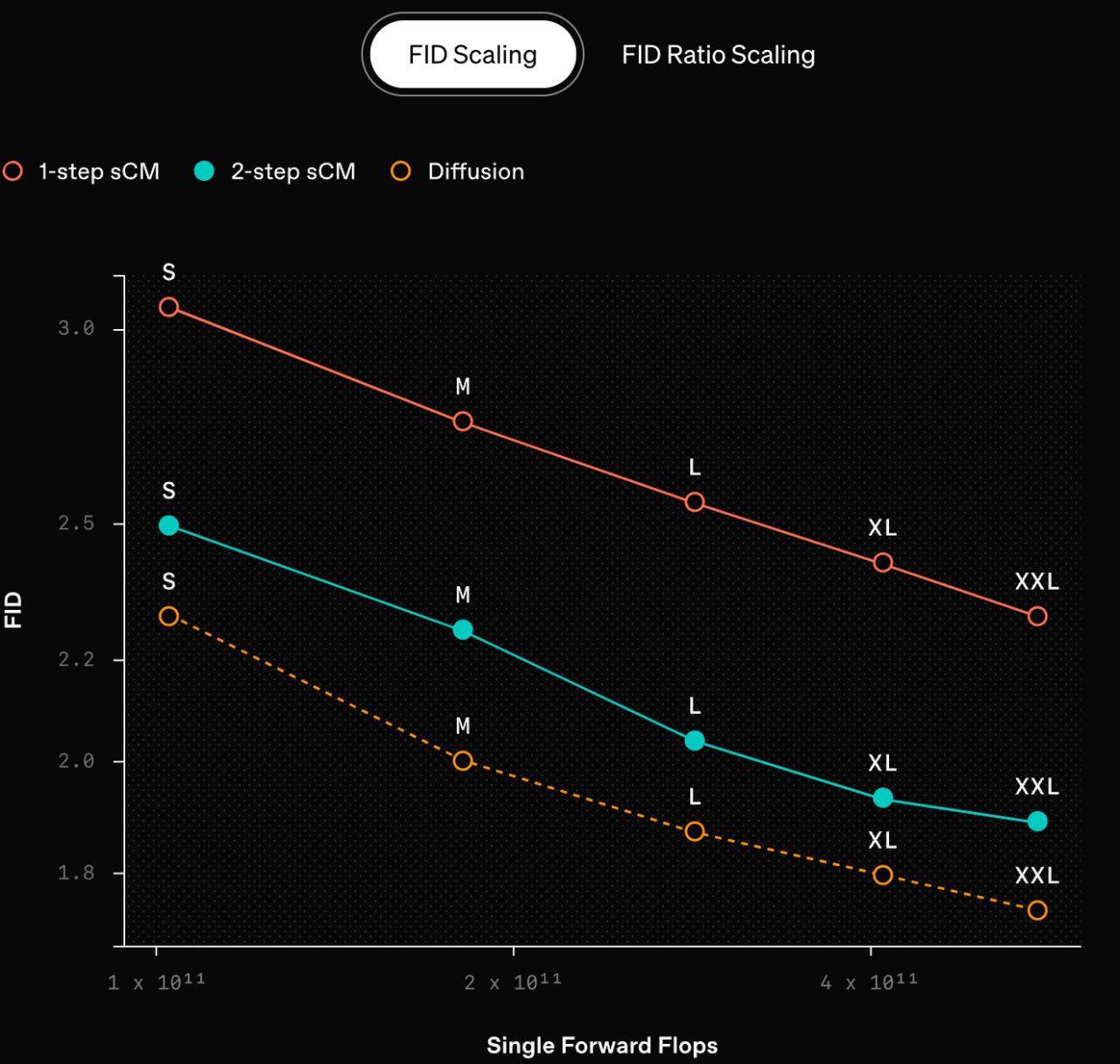
隨着模型規模的擴大,sCM 模型的改進程度與“教師”擴散模型的改進程度成正比。具體來説,樣本質量的相對差異(用 FID 分數的比率衡量)在幾個數量級的模型規模上保持一致,這導致樣本質量的絕對差異隨着規模的擴大而減小
此外,增加 sCM 的採樣步驟可以進一步縮小質量差距。值得注意的是,來自 sCM 的兩步樣本已經可以與來自“教師”擴散模型的樣本相媲美(FID 分數的相對差異小於 10%),而“教師”模型需要數百步才能生成樣本
sCM 與 VSD 的比較:
與變分分數蒸餾(VSD)相比,sCM 生成的樣本更加多樣化,並且在高引導尺度下更不容易出現模式坍塌,從而獲得更好的 FID 分數
sCM 的侷限性:
最好的 sCM 模型仍然需要預訓練的擴散模型來進行初始化和蒸餾,因此在圖像質量上與“老師”模型相比還是略遜一籌
FID 分數並不完美,有時候 FID 分數接近並不代表實際圖像質量也接近,反之亦然。所以,評估 sCM 的質量還是要根據具體應用場景來判斷
one more thing
OpenAI説的很清楚:
We believe these advancements will unlock new possibilities for real-time, high-quality generative AI across a wide range of domains
ChatGPT 11月30就兩歲了,Sora還沒有落地但開發主管都離職了跑路了,但是sCM的發佈説明OpenAI內部還在憋大招,sam altman也在暗示ChatGPT兩歲生日該發佈點什麼,也許就是實時高質量視頻生成大殺器sora?
實時高質量視頻生成大殺器sora有可能嗎?😄







{kind=link}