

目錄
剛剛!人工智能教父Geoffrey Hinton成為首個圖靈獎+諾貝爾物理學獎得主
人類歷史首次,圖靈獎獲得者計算機科學家AI教父Geoffrey Hinton獲得諾貝爾物理學獎,這是首次有人同時獲得計算機科學最高獎-圖靈獎和諾貝爾物理學獎。
2024年諾貝爾物理學獎新聞發佈會
2024年10月8日
瑞典皇家科學院決定將2024年諾貝爾物理學獎授予:

約翰·J·霍普菲爾德John J. Hopfield
普林斯頓大學,美國新澤西州
傑弗裏·E·辛頓Geoffrey Hinton
多倫多大學,加拿大
“表彰他們為人工神經網絡機器學習的奠基性發現和發明”
他們利用物理學訓練人工神經網絡
今年的兩位諾貝爾物理學獎得主使用物理學工具開發瞭如今強大的機器學習基礎方法。約翰·霍普菲爾德創造了一種關聯記憶,可以存儲和重構圖像及其他類型的數據模式。傑弗裏·辛頓發明了一種可以自主識別數據特性的算法,從而執行如識別圖像中特定元素的任務
當我們談論人工智能時,通常指的是使用人工神經網絡的機器學習。這項技術最初受大腦結構啓發。在人工神經網絡中,大腦的神經元由具有不同值的節點表示。這些節點通過類似於突觸的連接相互作用,連接可以被增強或削弱。網絡通過訓練,逐漸增強高值節點之間的連接。今年的獲獎者自20世紀80年代以來在人工神經網絡領域做出了重要貢獻
約翰·霍普菲爾德 發明了一種可以存儲和重現模式的網絡。可以將這些節點比作像素。_霍普菲爾德網絡_使用物理學中的理論來描述材料的特性,特別是原子自旋的能量——這使得每個原子都像一個微小的磁鐵。整個網絡的能量類似於物理學中的自旋系統。通過調整節點之間的連接值,保存的圖像能量降低。當網絡輸入失真或不完整的圖像時,它通過逐步更新節點值,降低網絡的能量,最終找到與輸入圖像最接近的保存圖像
傑弗裏·辛頓 基於霍普菲爾德網絡開發了一種新的網絡,即_玻爾茲曼機_。它可以學習識別特定類型數據中的特徵元素。辛頓利用統計物理學工具,訓練機器識別在運行時最可能出現的模式。玻爾茲曼機可以用於圖像分類或生成與訓練數據類似的新樣本。辛頓的工作推動了當前機器學習領域的快速發展。
“獲獎者的工作已帶來了巨大益處。在物理學中,人工神經網絡被廣泛用於開發具有特定性質的新材料等領域,”諾貝爾物理學委員會主席Ellen Moons表示
諾獎委員會給Geoffrey Hinton打電話通知時
Geoffrey Hinton:
"我現在住在加利福尼亞的一家廉價旅館裏,那裏的網絡和電話都不好。我本來打算今天做核磁共振掃描,但我不得不取消了!"
玻爾茲曼機:
玻爾茲曼機(Boltzmann Machine)是一種基於概率模型的人工神經網絡,由Geoffrey Hinton等人於1985年提出。它的設計靈感來自統計物理學中的玻爾茲曼分佈,主要用於解決複雜的數據處理和模式識別問題
玻爾茲曼機的核心思想是通過模擬神經元之間的隨機激活來尋找數據中的特徵或模式。它是一種“能量模型”,通過最小化一個稱為“能量函數”的指標來進行學習。具體來説,玻爾茲曼機會在其節點之間建立連接,每個節點都可以有一個二進制狀態(0或1),網絡通過調整節點之間的連接權重來減少整個系統的能量,從而更好地匹配輸入數據的特性。
它的工作過程包括兩部分:
- 正向傳播:根據輸入數據,激活網絡的節點,計算輸出
- 反向傳播(或對比散度):通過調整節點的連接權重,使得系統產生的輸出儘可能接近輸入的真實數據。
玻爾茲曼機最重要的一個變體是受限玻爾茲曼機(Restricted Boltzmann Machine, RBM),它去掉了節點之間的部分連接,簡化了計算,廣泛用於深度學習模型中的特徵提取和降維。
玻爾茲曼機雖然理論上很強大,但由於計算複雜度高,尤其是訓練過程需要大量計算資源,所以它在實際應用中並不常見。然而,它的概念為後續的深度學習模型奠定了基礎
獎沒有發錯:獲獎原因詳細解讀
今年的獲獎者使用物理學工具構建方法,為當今強大的機器學習奠定了基礎。John Hopfield 創建了一種可以存儲和重建信息的結構。Geoffrey Hinton 發明了一種可以獨立發現數據屬性的方法,該方法對現在使用的大型人工神經網絡變得非常重要
他們利用物理學尋找信息中的模式
許多人已經體驗過計算機如何在語言之間進行翻譯、解釋圖像甚至進行合理的對話。或許鮮為人知的是,這類技術長期以來對研究都非常重要,包括對海量數據的排序和分析。機器學習的發展在過去 15 到 20 年間呈爆炸式增長,並利用了一種稱為人工神經網絡的結構。如今,當我們談論人工智能時,通常指的就是這種技術
雖然計算機不能思考,但機器現在可以模仿記憶和學習等功能。今年的物理學獎獲得者幫助實現了這一點。他們利用物理學的基本概念和方法,開發了使用網絡結構來處理信息的技術
機器學習不同於傳統的軟件,傳統的軟件就像一種食譜。軟件接收數據,根據明確的描述進行處理並生成結果,就像有人收集食材並按照食譜進行處理,製作蛋糕一樣。與此相反,在機器學習中,計算機通過示例學習,使其能夠處理過於模糊和複雜的問題,這些問題無法通過分步説明來管理。一個例子是解釋圖片以識別其中的物體
模仿大腦
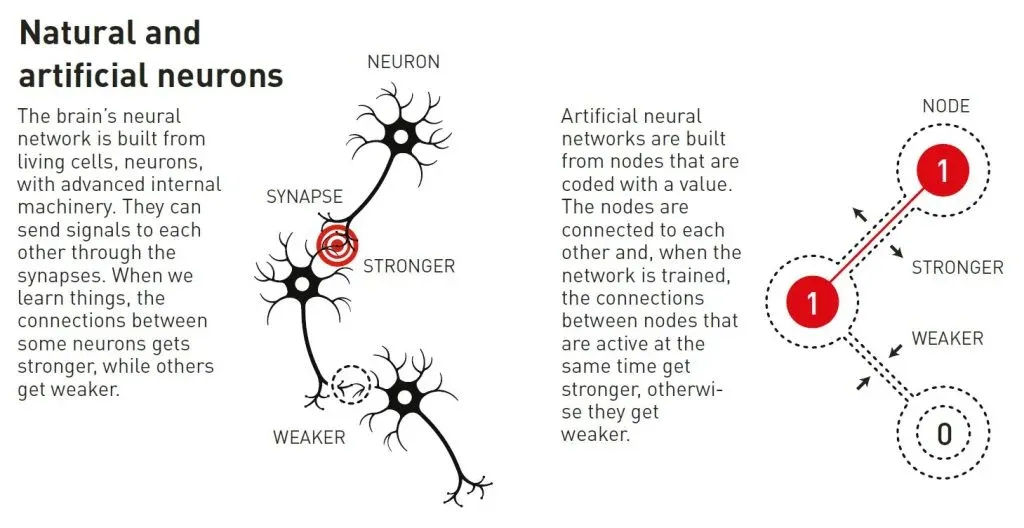
人工神經網絡使用整個網絡結構來處理信息。最初的靈感來自理解大腦如何工作的願望。在 20 世紀 40 年代,研究人員開始推理構成大腦神經元和突觸網絡的數學原理。另一個謎團來自心理學,這要感謝神經科學家 Donald Hebb 關於學習是如何發生的假設,因為神經元之間的連接在它們一起工作時會得到加強
後來,這些想法之後是嘗試通過構建人工神經網絡作為計算機模擬來重建大腦的網絡功能。在這些網絡中,大腦的神經元被賦予不同值的節點所模仿,而突觸則由節點之間的連接表示,這些連接可以加強或減弱。Donald Hebb 的假設仍然被用作通過稱為訓練的過程更新人工網絡的基本規則之一
自然和人工神經元
在 20 世紀 60 年代末,一些令人沮喪的理論結果導致許多研究人員懷疑這些神經網絡永遠不會有任何實際用途。然而,人們對人工神經網絡的興趣在 20 世紀 80 年代重新燃起,當時幾個重要的想法產生了影響,包括今年獲獎者的工作。
聯想記憶
想象一下,你正試圖記住一個你很少使用的相當不尋常的單詞,例如電影院和演講廳中常見的傾斜地板的單詞。你在腦海中搜索。它類似於坡道......也許是 rad...ial?不,不是那個。是 Rake!
這個通過相似單詞搜索找到正確單詞的過程讓人想起物理學家 John Hopfield 在 1982 年發現的聯想記憶。Hopfield 網絡可以存儲模式,並且有一種重建它們的方法。當網絡被賦予一個不完整或略有扭曲的模式時,該方法可以找到最相似的存儲模式
Hopfield 之前曾利用他的物理學背景來探索分子生物學中的理論問題。當他被邀請參加一個關於神經科學的會議時,他遇到了關於大腦結構的研究。他對學到的東西着迷,並開始思考簡單神經網絡的動力學。當神經元一起作用時,它們可以產生新的、強大的特徵,而這些特徵對於只關注網絡各個組成部分的人來説是不明顯的
1980 年,Hopfield 離開了普林斯頓大學的職位,在那裏他的研究興趣使他超出了他的物理學同事工作的領域,並搬到了整個大陸的另一邊。他接受了在南加州帕薩迪納的加州理工學院(加州理工學院)的化學和生物學教授職位。在那裏,他可以使用計算機資源進行免費實驗,並發展他對神經網絡的想法
然而,他並沒有放棄他的物理學基礎,他在那裏找到了理解具有許多協同工作的小組件的系統如何產生新的、有趣的現象的靈感。他特別受益於學習了磁性材料,這些材料由於其原子自旋而具有特殊的特性——這種特性使每個原子都成為一個小磁鐵。相鄰原子的自旋相互影響;這可以允許形成自旋方向相同的疇。他能夠通過使用描述材料如何在自旋相互影響時發展的物理學來創建具有節點和連接的模型網絡
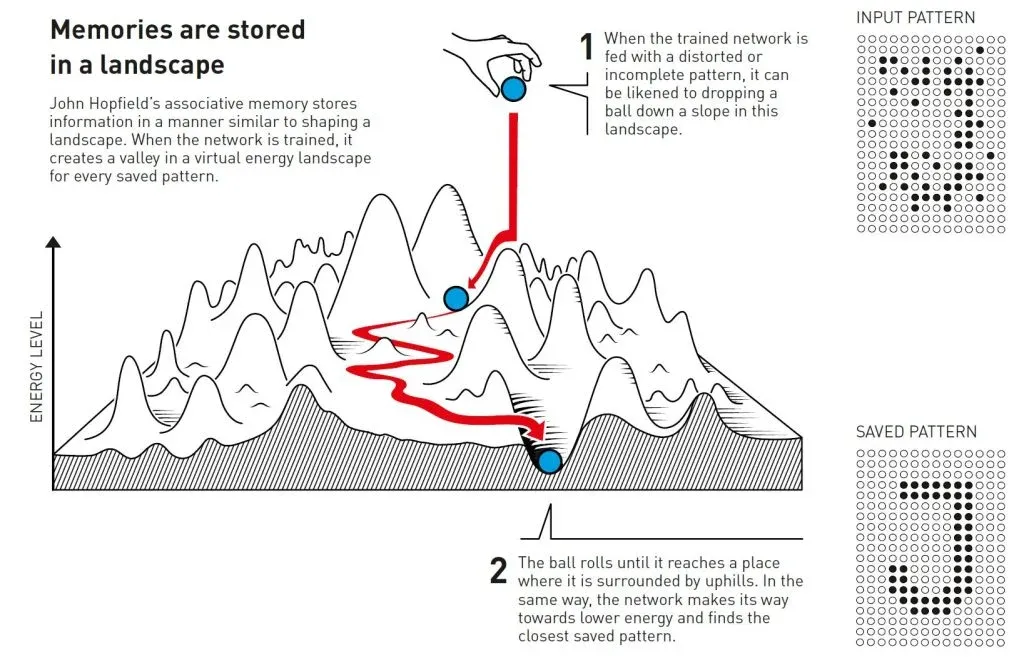
網絡將圖像保存在景觀中
Hopfield 構建的網絡具有通過不同強度的連接連接在一起的節點。每個節點都可以存儲一個單獨的值——在 Hopfield 的第一項工作中,這可以是 0 或 1,就像黑白圖片中的像素一樣
Hopfield 用一個等效於物理學中自旋系統能量的屬性來描述網絡的整體狀態;能量是使用一個公式計算的,該公式使用節點的所有值和它們之間連接的所有強度。Hopfield 網絡通過將圖像饋送到節點進行編程,節點被賦予黑色(0)或白色(1)的值。然後使用能量公式調整網絡的連接,以便保存的圖像獲得低能量。當另一個模式被饋送到網絡時,有一個規則,用於逐個遍歷節點,並檢查如果該節點的值發生更改,網絡是否具有更低的能量。如果結果是黑色像素變為白色,則能量會降低,它會改變顏色。此過程一直持續到不可能找到任何進一步的改進為止。當達到這一點時,網絡通常已經再現了訓練它的原始圖像
如果你只保存一個模式,這可能看起來並不那麼引人注目。也許你想知道為什麼不直接保存圖像本身,然後將其與正在測試的另一個圖像進行比較,但 Hopfield 的方法很特殊,因為可以在同一時間保存多張圖片,並且網絡通常可以區分它們
Hopfield 將在網絡中搜索保存狀態比作在一個充滿峯谷的景觀中滾動一個球,摩擦力會減慢它的運動。如果球落在某個特定位置,它會滾入最近的山谷並在那裏停止。如果網絡被賦予一個與保存模式之一相近的模式,它將以同樣的方式繼續前進,直到它最終落在能量景觀中一個山谷的底部,從而找到其記憶中最接近的模式
Hopfield 網絡可用於重建包含噪聲或部分擦除的數據
Hopfield 和其他人繼續開發 Hopfield 網絡工作原理的細節,包括可以存儲任何值的節點,而不僅僅是零或一。如果你把節點想象成圖片中的像素,它們可以有不同的顏色,而不僅僅是黑色或白色。改進的方法使保存更多圖片以及區分它們成為可能,即使它們非常相似。識別或重建任何信息也是可能的,只要它是從許多數據點構建的
使用 19 世紀物理學進行分類
記住圖像是一回事,但解釋它所描繪的內容需要更多
即使是很小的孩子也可以指着不同的動物,並自信地説出它是狗、貓還是松鼠。他們有時可能會弄錯,但很快他們幾乎每次都是正確的。即使沒有看到任何圖表或對物種或哺乳動物等概念的解釋,孩子也能學會這一點。在遇到幾種類型的動物的幾個例子後,不同的類別會在孩子的大腦中各就各位。人們通過體驗周圍的環境來學習識別貓、理解單詞或進入房間並注意到某些東西已經改變
當 Hopfield 發表關於聯想記憶的文章時,Geoffrey Hinton 正在美國匹茲堡的卡內基梅隆大學工作。他之前在英格蘭和蘇格蘭學習過實驗心理學和人工智能,並且想知道機器是否可以學會以類似於人類的方式處理模式,找到自己的類別來分類和解釋信息。Hinton 與他的同事 Terrence Sejnowski 一起,從 Hopfield 網絡開始,並使用統計物理學的思想對其進行了擴展,以構建新的東西
統計物理學描述了由許多相似元素組成的系統,例如氣體中的分子。跟蹤氣體中所有單獨的分子很困難或不可能,但可以將它們作為一個整體來考慮,以確定氣體的總體特性,如壓力或温度。氣體分子以不同的速度在其體積中擴散,但仍然會產生相同的集體特性,有很多種可能的方式
可以使用統計物理學來分析各個組件可以共同存在的狀態,並計算它們發生的概率。某些狀態比其他狀態更有可能;這取決於可用能量的數量,這是由 19 世紀物理學家路德維希·玻爾茲曼在一個方程中描述的。Hinton 的網絡利用了這個方程式,該方法於 1985 年以引人注目的名字玻爾茲曼機發表
識別同一類型的新示例
玻爾茲曼機通常與兩種不同類型的節點一起使用。信息被饋送到一組節點,稱為可見節點。其他節點形成一個隱藏層。隱藏節點的值和連接也對網絡整體的能量有貢獻
該機器的運行方式是應用一個規則,一次更新一個節點的值。最終,機器將進入一個狀態,其中節點的模式可以更改,但網絡整體的屬性保持不變。然後,每個可能的模式將有一個特定的概率,該概率由網絡的能量根據玻爾茲曼方程確定。當機器停止時,它已經創建了一個新的模式,這使得玻爾茲曼機成為生成模型的早期示例。
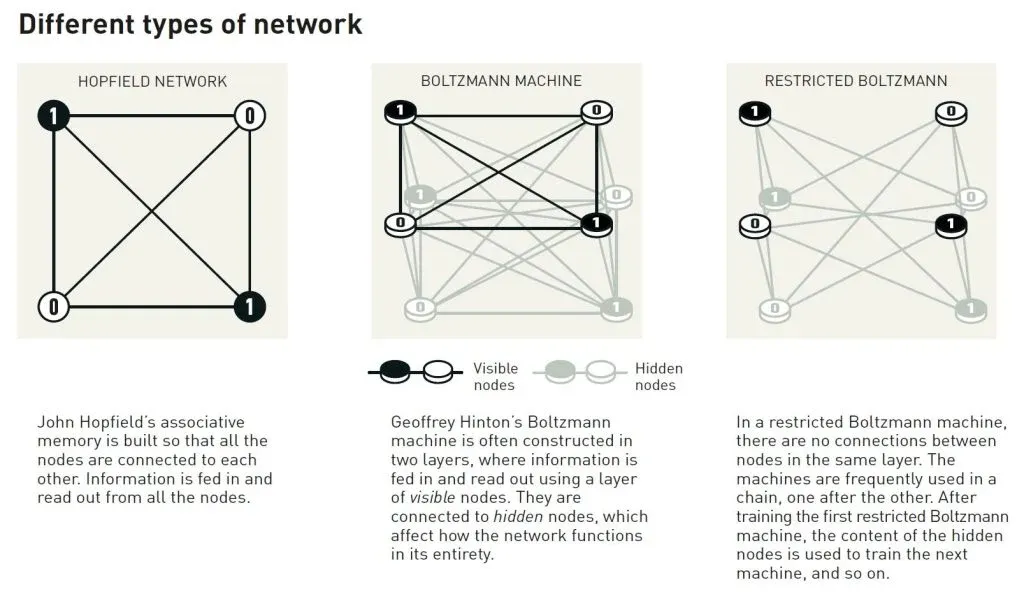
玻爾茲曼機可以學習——不是通過指令,而是通過被給出的示例。它通過更新網絡連接中的值來進行訓練,以便在訓練時饋送到可見節點的示例模式在機器運行時具有最高的發生概率。如果在訓練過程中重複相同的模式多次,則該模式的概率甚至更高。訓練還會影響輸出與機器訓練示例相似的新的模式的概率
經過訓練的玻爾茲曼機可以識別它以前從未見過信息中的熟悉特徵。想象一下遇到一個朋友的兄弟姐妹,你馬上就能看出他們一定是相關的。同樣,玻爾茲曼機如果屬於訓練材料中的類別,就可以識別一個全新的示例,並將其與不同的材料區分開來
在其原始形式中,玻爾茲曼機效率相當低,並且需要很長時間才能找到解決方案。當它以各種方式發展時,事情變得更加有趣,Hinton 繼續探索這些方式。後來的版本已經變薄了,因為一些單元之間的連接已經被移除。事實證明,這可能會使機器更有效率
在 20 世紀 90 年代,許多研究人員對人工神經網絡失去了興趣,但 Hinton 是繼續在該領域工作的人之一。他還幫助開啓了激動人心的新成果的爆炸式增長;2006 年,他和他的同事 Simon Osindero、Yee Whye Teh 和 Ruslan Salakhutdinov 開發了一種用一系列分層的玻爾茲曼機預訓練網絡的方法,一層疊一層。這種預訓練為網絡中的連接提供了一個更好的起點,從而優化了其訓練以識別圖片中的元素
玻爾茲曼機通常用作較大網絡的一部分。例如,它可以用來根據觀眾的喜好推薦電影或電視劇
機器學習——今天和明天
由於他們在 1980 年代及以後的工作,John Hopfield 和 Geoffrey Hinton 幫助奠定了大約在 2010 年開始的機器學習革命的基礎
我們現在所見證的發展之所以成為可能,是因為可以訪問大量的可用數據來訓練網絡,以及計算能力的巨大增長。今天的人工神經網絡通常非常龐大,由許多層構成。這些被稱為深度神經網絡,它們的訓練方式被稱為深度學習
快速瀏覽一下 Hopfield 1982 年關於聯想記憶的文章,可以從一些角度看待這一發展。在其中,他使用了包含 30 個節點的網絡。如果所有節點都相互連接,則有 435 個連接。節點有它們的值,連接有不同的強度,總共不到 500 個參數需要跟蹤。他還嘗試了包含 100 個節點的網絡,但考慮到他當時使用的計算機,這太複雜了。我們可以將其與今天的大型語言模型進行比較,這些模型構建為網絡,可以包含超過一萬億個參數(一百萬個百萬)
許多研究人員現在正在開發機器學習的應用領域。哪些是最可行的還有待觀察,同時,圍繞這項技術的發展和使用的倫理問題也有廣泛的討論
由於物理學為機器學習的發展貢獻了工具,因此有趣的是看到物理學作為一門研究領域也如何受益於人工神經網絡。機器學習長期以來一直用於我們可能從以前的諾貝爾物理學獎中熟悉的領域。這些包括使用機器學習來篩選和處理發現希格斯玻色子所需的大量數據。其他應用包括減少黑洞碰撞產生的引力波測量中的噪聲,或尋找系外行星
近年來,這項技術也開始用於計算和預測分子和材料的特性——例如計算蛋白質分子的結構,這決定了它們的功能,或者找出哪種新版本的材料可能具有最適合用於更高效太陽能電池的特性
基於以上原因
瑞典皇家科學院決定將 2024 年諾貝爾物理學獎授予:

JOHN J. HOPFIELD
1933 年出生於美國伊利諾伊州芝加哥。1958 年獲得美國紐約州伊薩卡康奈爾大學博士學位。美國新澤西州普林斯頓大學教授。
GEOFFREY E. HINTON
1947 年出生於英國倫敦。1978 年獲得英國愛丁堡大學博士學位。加拿大多倫多大學教授。
Geoffrey Hinton從不被理解到獲得圖靈獎和諾貝爾物理學獎
辛頓實至名歸,值得這個獎,幾十年來不被導師和領導看好,甚至拿不到經費還堅持走別人認為的“野路子”,太難得了:
Geoffrey Hinton 是神經網絡領域的先驅,被譽為“深度學習之父”。他對神經網絡的研究在今天推動了人工智能的重大進展,但在他開始研究神經網絡的早期,他確實遇到了很多懷疑和阻力。這裏有一些有趣的背景故事和趣聞:
與主流科學界的對立: 在20世紀80年代,主流的人工智能研究主要集中在符號主義(symbolism),即通過明確的規則和邏輯來實現智能行為。當時,神經網絡這種基於生物學的方式被許多專家認為是“野路子”,Hinton 的研究方向因此在學術界並不受歡迎。即便如此,他堅持自己的信念,認為模仿大腦的工作機制可以帶來突破。
導師和同事的懷疑: Hinton 早期的導師和同事並不看好他的研究方向,甚至認為神經網絡的想法是個錯誤。Hinton 的領導、當時的著名計算機科學家們對神經網絡的前景持懷疑態度,認為這種方法太過簡單,不能有效地解決複雜的計算問題。這也讓他很難獲得研究經費和支持。
堅持信念與自費研究: 面對資金短缺和主流科學界的冷遇,Hinton 甚至自費繼續進行神經網絡的研究。在1980年代中期,他與David Rumelhart和Ronald J. Williams共同提出了反向傳播算法(backpropagation),這成為神經網絡訓練的重要突破。然而,即便這個算法獲得了極大的關注,神經網絡依然沒有迅速流行起來。Hinton 幾乎是靠自己的信念和少數同事的支持在維持這條“冷門”道路。
圖靈獎得主的“反叛”: Hinton 的家庭背景也非常有趣,他的曾祖父是邏輯學家 George Boole(布爾代數的發明者),Hinton 出身於一個非常有學術氛圍的家庭。但正因為如此,Hinton 也有一種反叛精神。他曾開玩笑説,他選擇研究神經網絡正是為了與自己所在的傳統符號主義流派“對着幹”。
Google 爭相搶人的故事: 到2012年,Hinton 和他的團隊通過一種叫做“深度卷積神經網絡”的技術,在ImageNet比賽中取得了令人矚目的成績,徹底改變了圖像識別的領域。這一突破使得Google、Facebook和其他科技巨頭爭相挖他。最終,Google 以其巨大的資源支持贏得了這場人才爭奪戰,Hinton 加入了Google,繼續推動深度學習的發展
Hinton 的故事展示了一個科學家堅持信念、逆流而上的過程。在主流不看好的情況下,他堅守了自己的研究,最終成就瞭如今的深度學習和人工智能革命。
各路人馬對Geoffrey Hinton獲得諾獎反映
馬斯克xAI聯合創始人Greg Yang:

歐洲核子中心:

人工智能教母李飛飛:
洛桑聯邦理工學院教授Lenka Zdeborova:

英偉達高級研究科學家jim fan:








{kind=link}