

目錄
AI 大模型經常“一本正經地胡説八道”,這個問題 OpenAI 也頭疼!現在,他們祭出了新武器—— SimpleQA,並已正式開源,這是一個全新的事實性基準測試,專門用來檢測大模型回答事實性問題的準確性!OpenAI 的研究科學家 Jason Wei 表示,由於此前一直缺乏一個好的事實性基準測試,所以他們團隊決定自己動手,創建一個簡單、可靠、易用的評估工具,供所有 AI 研究人員使用

SimpleQA 究竟有何過人之處?總結起來有三大特點:
設置簡單到爆: 包含 4000 道由人類編寫、清晰無歧義的事實性問題,每個問題都只有一個無可爭議的正確答案。模型的回答會被自動評分器評為“正確”、“錯誤”或“未嘗試”
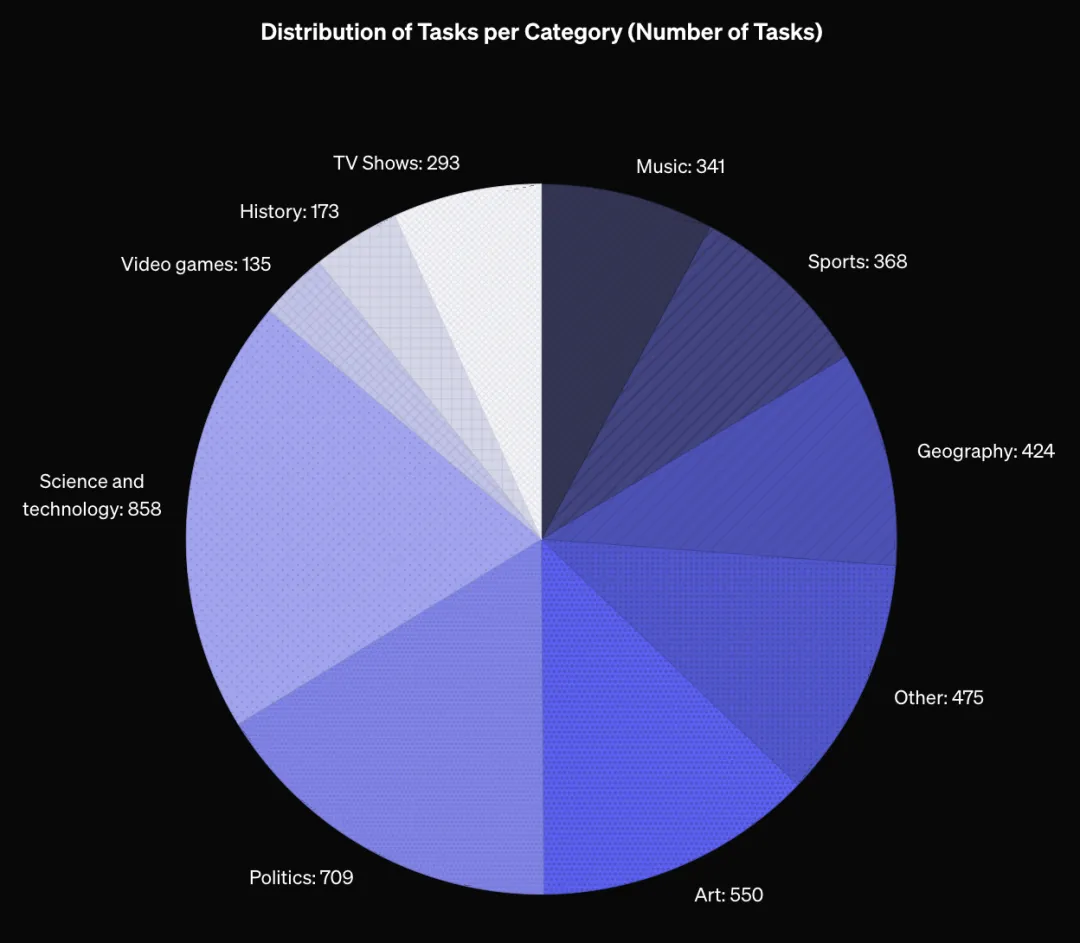
挑戰性大,前沿模型也跪了: SimpleQA 對目前最先進的大模型也構成了巨大挑戰!連 o1-preview 和 Claude Sonnet 3.5 的準確率都不到 50%!
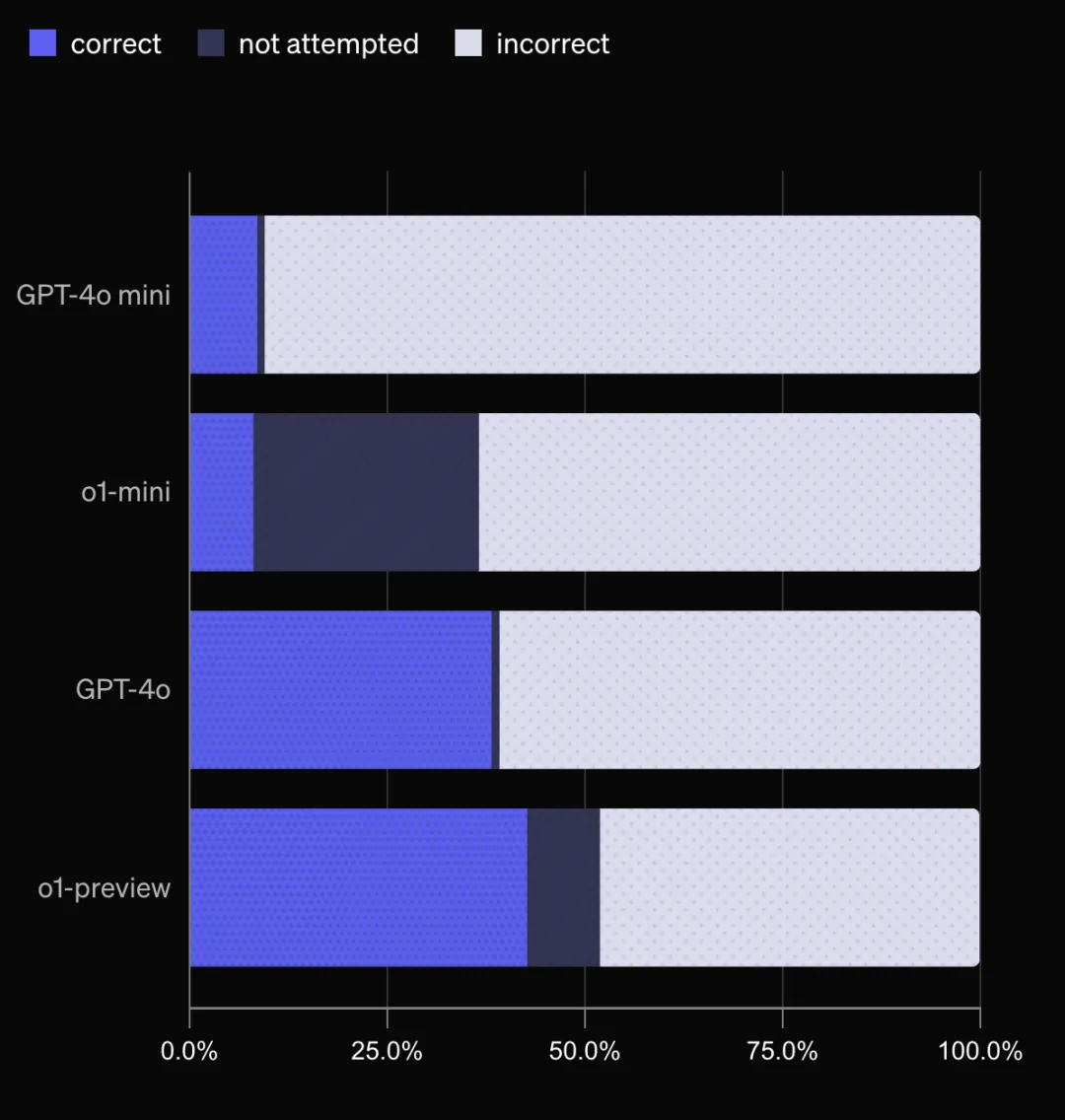
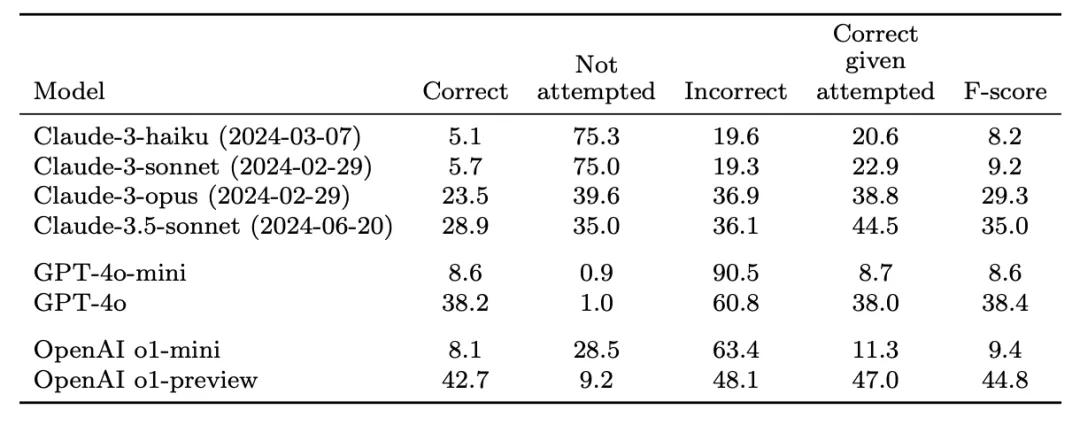
參考答案准確度高,經得起時間考驗:
所有问题都经过精心设计,参考答案经过两位独立标注员的验证,确保准确可靠。而且,这些问题的设计也考虑到了时效性,即使 5 年或 10 年后,SimpleQA 仍然是一个有用的基准测试,相当耐用!
SimpleQA是如何構建的?
OpenAI僱傭了AI訓練師從網上收集問題和答案,並制定了嚴格的標準:答案必須唯一、準確、不會隨時間變化,而且大多數問題必須能誘導GPT-4o或GPT-3.5產生“幻覺”。為了保證質量,還有第二位AI訓練師獨立回答每個問題,只有兩位訓練師答案一致的問題才會被收錄。最後,還有第三位訓練師對1000個隨機問題進行驗證,最終估算出數據集的固有錯誤率約為3%
如何用SimpleQA比較大模型?
用一個經過prompt的ChatGPT分類器對模型的答案進行評分,分為“正確”、“錯誤”和“未嘗試”三種。目標是儘可能多地正確回答問題,同時最小化錯誤答案的數量。測試結果顯示,o1-preview效果最佳。小模型的正確率不如大模型,這可能是因為小模型的知識儲備較少。o1-preview和o1-mini更傾向於選擇“未嘗試”,這可能是因為它們能夠利用推理能力識別自己不知道答案的情況,而不是胡編亂造
SimpleQA還能幹啥?
除了評估事實性,SimpleQA還可以用來測量大模型的“校準”程度,也就是模型“知之為知之,不知為不知”的能力。
置信度與準確率: 通過讓模型給出答案的同時給出置信度,然後比較置信度和實際準確率之間的關係,就能看出模型的校準程度。結果表明,模型普遍高估了自己的置信度,還有很大的改進空間。o1-preview比o1-mini校準程度更好,GPT-4比GPT-4-mini校準程度更好,這與之前的研究結果一致,即更大的模型校準程度更好
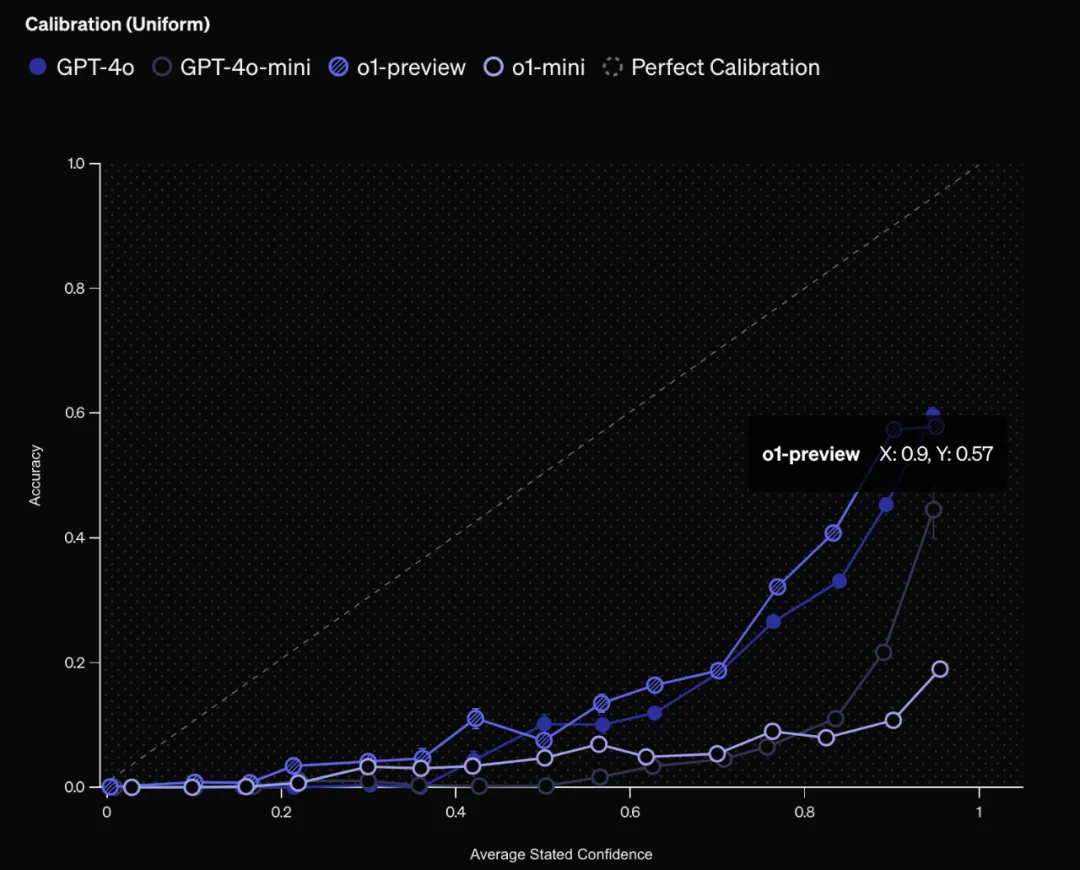
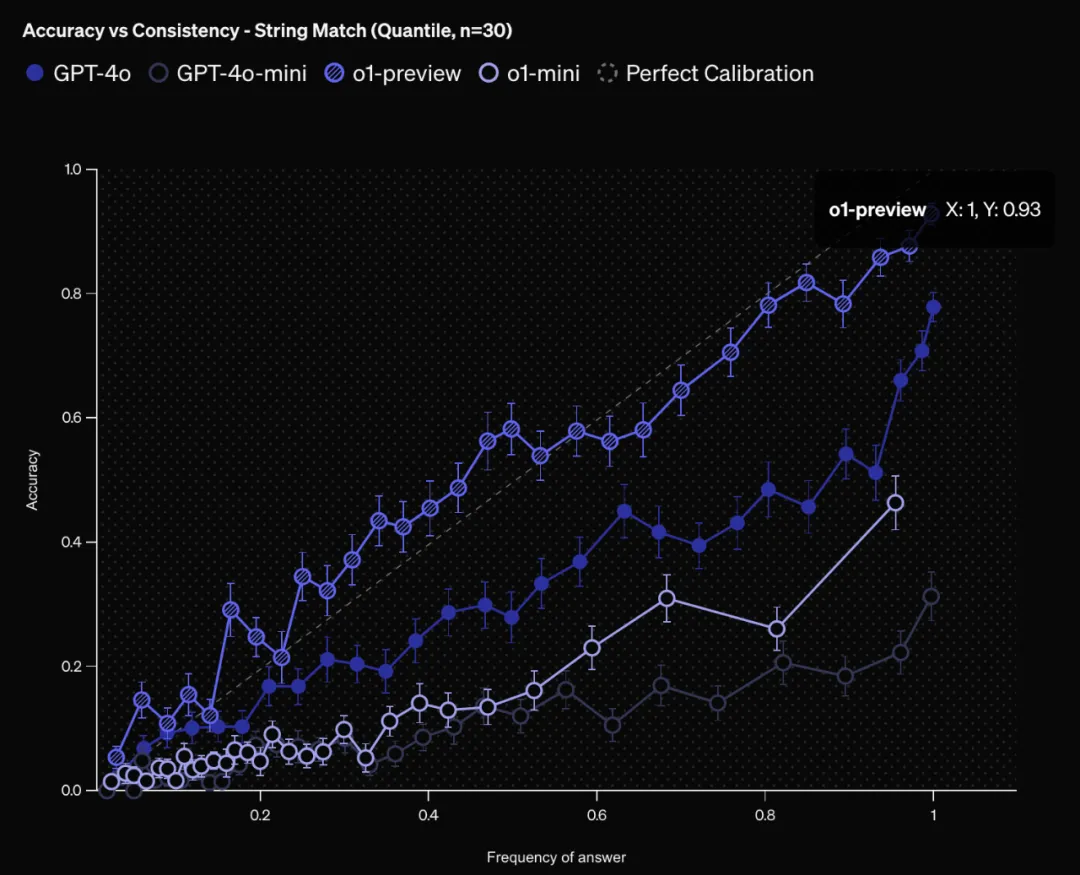
答案頻率與準確率: 另一種測量校準的方法是將同一個問題問模型100次。由於語言模型在重複嘗試時可能會產生不同的答案,因此可以評估特定答案的出現頻率與其正確性是否相符。更高的頻率通常表明模型對答案更有信心。o1-preview 在這方面表現最好,其答案的頻率與準確率基本一致。與通過置信度判斷的校準結果類似,o1-preview 比 o1-mini 的校準程度更好,GPT-4 比 GPT-4-mini 的校準程度更好
限制
SimpleQA 是評估前沿模型事實性的一個簡單但具有挑戰性的基準。SimpleQA 的主要侷限性在於其範圍--雖然 SimpleQA 非常準確,但它只能在具有單一可驗證答案的簡短事實查詢這一受限環境下測量事實性。提供符合事實的簡短回答的能力是否與撰寫包含大量事實的冗長回答的能力相關,這仍然是一個有待研究的問題
開源地址:
https://github.com/openai/simple-evals/
參考:
https://openai.com/index/introducing-simpleqa
SimpleQA Paper:
https://cdn.openai.com/papers/simpleqa.pdf







{kind=link}